LeetCode 每日一题 0601-0607(2020)
2020-06-01 至 2020-06-07 LeetCode 每日一题
[0601] 1431. Kids With the Greatest Number of Candies(easy)
儿童节专题题目:1431.Kids With the Greatest Number of Candies(拥有最多糖果的孩子)
keyword:数组与指针
Question
Given the array candies and the integer extraCandies, where candies[i] represents the number of candies that the ith kid has.
For each kid check if there is a way to distribute extraCandies among the kids such that he or she can have the greatest number of candies among them. Notice that multiple kids can have the greatest number of candies.
Example 1: 1
2Input: candies = [2,3,5,1,3], extraCandies = 3
Output: [true,true,true,false,true]
Example 2: 1
2Input: candies = [4,2,1,1,2], extraCandies = 1
Output: [true,false,false,false,false]
Example 3: 1
2Input: candies = [12,1,12], extraCandies = 10
Output: [true,false,true]
Intuition
Children's day special, simple question. Find the maximum value firstly, and then walk through it to make judgment one by one.
Code
1 | |
[0602] 面试题64. 求1+2+…+n
[0603] 837. New 21 Game(medium)
Question
keyword:动态规划
Alice plays the following game, loosely based on the card game "21".
Alice starts with 0 points, and draws numbers while she has less than K points. During each draw, she gains an integer number of points randomly from the range [1, W], where W is an integer. Each draw is independent and the outcomes have equal probabilities.
Alice stops drawing numbers when she gets K or more points. What is the probability that she has N or less points?
Example 1: 1
2Input: N = 10, K = 1, W = 10
Output: 1.00000
Example 2: 1
2Input: N = 6, K = 1, W = 10
Output: 0.60000
Example 3: 1
2Input: N = 21, K = 17, W = 10
Output: 0.73278
Answers will be accepted as correct if they are within 10^-5 of the correct answer. The judging time limit has been reduced for this question.
Intuition
w: 抽牌范围为 0-w k: 抽牌条件得分小于k N: 计算得分小于等于N的概率
动态规划问题的求解分为三步
1、确定状态

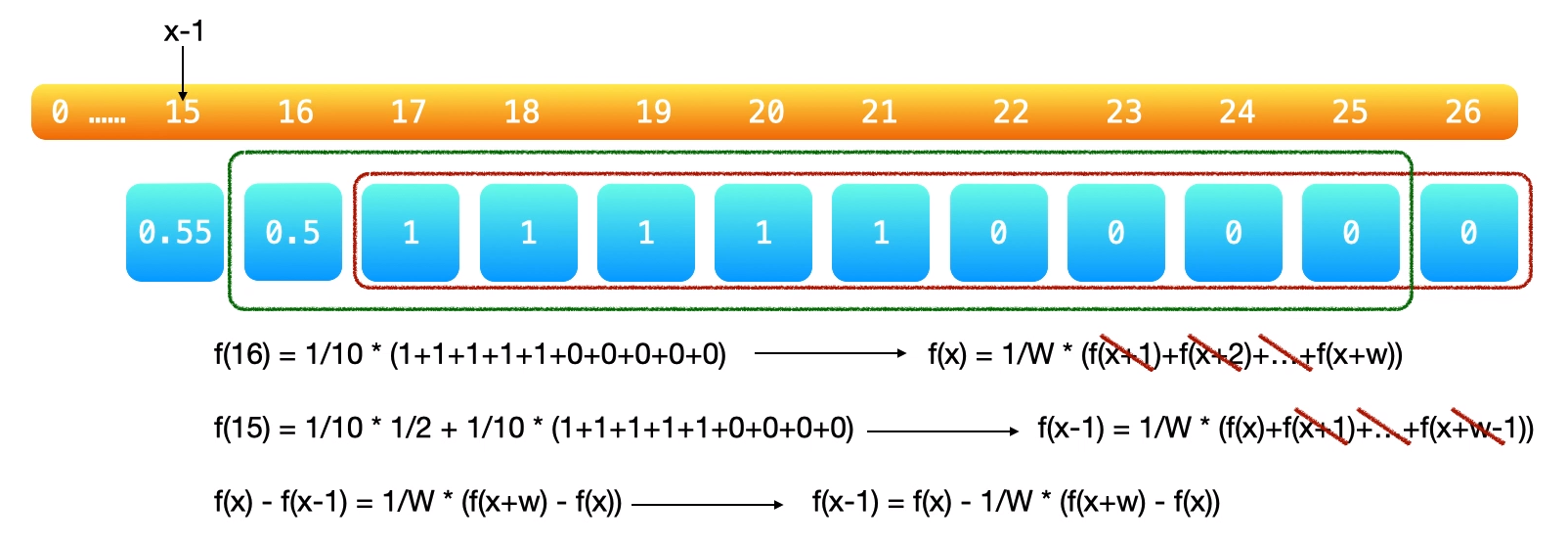
设 \(f(s)\) 为得分为 \(s\) 时,再抽取一次,新的得分小于等于 \(N\) 的概率。则爱丽丝以 0 分开始,并在她的得分少于 K 分时抽取数字,爱丽丝的分数不超过 N 的概率就是 \(f(0)\) 。以 N = 21, K = 17, W = 10,为例子\(f(16) = \frac{1}{10} \times (1+1+1+1+1+0+0+0+0+0)=\frac{}{}\) 。第一个 \(+1\) 代表抽到 \(1\) 之后,新得分(17)小于等于 \(N\) (21)的概率为 \(1\)(也就是100%)。同理,第二个 \(+1\) 代表抽到 \(2\) 之后,新得分(18)小于等于 \(N\)(21)的概率为 \(1\)(也就是100%)。第一个 \(+0\) 代表抽到 \(6\) 之后,新得分(22)小于等于 \(N\) (21)的概率为 \(0\),以此类推。则上述过程可公式化为 \(f(s) = \frac{1}{w} \times f(s+1) + f(s+2) + ... + f(s+w)\)。
2、确定状态转移方程

\(f(15) = \frac{1}{10} \times (\frac{1}{2} + 1 + 1 + 1 + 1 + 1 + 0 + 0 + 0 + 0)\)。第一个 \(+\frac{1}{2}\) 代表抽到 \(1\) 之后,新得分(16)小于等于 \(N\) (21)的概率为 \(f(16)=\frac{1}{2}\)。第一个 \(+1\) 代表抽到 \(2\) 之后,新得分(17)小于等于 \(N\) (21)的概率为 \(1\)(也就是100%)。综上,可得状态转移方程为:
\[ f(s-1) = \frac{1}{w} \times (f(s) + f(s) + ... + f(x+w-1)) \]
则,\(f(0) = \frac{1}{10} \times (f(1) + f(2) + ... + f(10))\),从后(\(f(16)\) )往前计算 \(f(0)\)。这里可以做个优化,\(f(s)\) 和 \(f(s-1)\) 之间存在重复部分,去掉重复部分之后,状态转移方程为: \[
f(s-1) = f(s) - \frac{1}{w} \times (f(s+w) - f(s))
\] 
3、确定初始化状态
由于是从后往前计算,所以要初始化一个 k+w 的数组,初始化为0。然后,再将 k-N (17-21)部分改为 1。接着计算 k-1 位置( \(f(16)\) )的值, f(k-1) = min(N - K + 1, W) / w ,min(N - K + 1, W) 为 \(f(16)\) 要 \(+1\) 的个数,N = 21, K = 17, W = 10 时,min(N - K + 1, W)=5,也就是 \(f(16)\) \(+1\) 的个数为 \(5\),最终 \(f(16) = \frac{5}{10} = \frac{1}{2}\)/。
完成以上步骤之后,就可以从\(k-2\)往前,利用 \(f(s-1) = f(s) - \frac{1}{w} \times (f(s+w) - f(s))\) 计算 \(f(0)\) 了。
复杂度分析
时间复杂度:\(O(\min(N, K+W))\)。即需要计算的 dp 值的数量 \(\min(N, K+W-1)\)。 空间复杂度:\(O(K+W)\)。创建了一个长度为 \(K+W+1\) 的数组 dp。
参考连接
Code
1 | |
[0604] 238. Product of Array Except Self (medium)
keyword: 数组与指针
Question
Given an array nums of n integers where n > 1, return an array output such that output[i] is equal to the product of all the elements of nums except nums[i].
Example: 1
2Input: [1,2,3,4]
Output: [24,12,8,6]
Note: Please solve it without division and in \(O(n)\).
Follow up: Could you solve it with constant space complexity (常数空间复杂度)? (The output array does not count as extra space for the purpose of space complexity analysis.)
Intuition
我们不必将所有数字的乘积除以给定索引处的数字得到相应的答案,而是利用索引左侧所有数字的乘积和右侧所有数字的乘积(即前缀与后缀)相乘得到答案。
算法
- 初始化两个空数组
L和R。对于给定索引i,L[i]代表的是i左侧所有数字的乘积,R[i]代表的是i右侧所有数字的乘积。 - 我们需要用两个循环来填充
L和R数组的值。对于数组L,L[0]应该是1,因为第一个元素的左边没有元素。对于其他元素:L[i] = L[i-1] * nums[i-1]。 - 同理,对于数组
R,R[length-1]应为1。length指的是输入数组的大小。其他元素:R[i] = R[i+1] * nums[i+1]。 - 当
R和L数组填充完成,我们只需要在输入数组上迭代,且索引i处的值为:L[i] * R[i]。
时间复杂度:\(O(N)\),空间复杂度:\(O(N)\)。
由于输出数组不算在空间复杂度内,那么我们可以将 L 或 R 数组用输出数组来计算。先把输出数组当作 L 数组来计算,然后再动态构造 R 数组得到结果。让我们来看看基于这个思想的算法。
算法
- 初始化
answer数组,对于给定索引i,answer[i]代表的是i左侧所有数字的乘积。 - 构造方式与之前相同,只是我们试图节省空间,先把
answer作为方法一的L数组。 - 这种方法的唯一变化就是我们没有构造
R数组。而是用一个遍历来跟踪右边元素的乘积。并更新数组answer[i]=answer[i]。然后R更新为R=R*nums[i],其中变量R表示的就是索引右侧数字的乘积。
Code
1 | |
[0605] 54. Spiral Matrix (easy)
LeetCode 54. 螺旋矩阵(中)& 剑指offer 面试题29. 顺时针打印矩阵
keyword: 数组与指针
[0606] 128. Longest Consecutive Sequence (hard)
keyword: 数组与指针,并查集
Question
Given an unsorted array of integers, find the length of the longest consecutive elements sequence. Your algorithm should run in \(O(n)\) complexity.
示例: 1
2Input: [100, 4, 200, 1, 3, 2]
Output: 4
Intuition
方法一
初始化的时候先把数组里每个元素初始化为他的下一个数; 并的时候找他能到达的最远的数字就可以了。
方法二
用一个哈希表存储数组中的数,这样查看一个数是否存在即能优化至 \(O(1)\) 的时间复杂度。
仅仅是这样我们的算法时间复杂度最坏情况下还是会达到 \(O(n^2)\)(即外层需要枚举 \(O(n)\) 个数,内层需要暴力匹配 \(O(n)\) 次),无法满足题目的要求。但仔细分析这个过程,我们会发现其中执行了很多不必要的枚举,如果已知有一个 \(x, x+1, x+2, \cdots, x+y\) 的连续序列,而我们却重新从 \(x+1,x+2\)或者是 \(x+y\) 处开始尝试匹配,那么得到的结果肯定不会优于枚举 \(x\) 为起点的答案,因此我们在外层循环的时候碰到这种情况跳过即可。那么怎么判断是否跳过呢?由于我们要枚举的数 \(x\) 一定是在数组中不存在前驱数 \(x-1\) 的,不然按照上面的分析我们会从 \(x-1\) 开始尝试匹配,因此我们每次在哈希表中检查是否存在 \(x-1\) 即能判断是否需要跳过了。
增加了判断跳过的逻辑之后,时间复杂度是多少呢?外层循环需要 \(O(n)\) 的时间复杂度,只有当一个数是连续序列的第一个数的情况下才会进入内层循环,然后在内层循环中匹配连续序列中的数,因此数组中的每个数只会进入内层循环一次。根据上述分析可知,总时间复杂度为 \(O(n)\),符合题目要求。
Code
- 方法一
1 | |
- 方法二
1 | |
[0607] Word Ladder II (hard)
keyword: 广度优先搜索、回溯算法
Question
Given two words (beginWord and endWord), and a dictionary's word list, find all shortest transformation sequence(s) from beginWord to endWord, such that:
Only one letter can be changed at a time Each transformed word must exist in the word list. Note that beginWord is not a transformed word. Note:
Return an empty list if there is no such transformation sequence. All words have the same length. All words contain only lowercase alphabetic characters. You may assume no duplicates in the word list. You may assume beginWord and endWord are non-empty and are not the same.
Example 1: 1
2
3
4Input:
beginWord = "hit",
endWord = "cog",
wordList = ["hot","dot","dog","lot","log","cog"]1
2
3
4[
["hit","hot","dot","dog","cog"],
["hit","hot","lot","log","cog"]
]1
2
3
4Input:
beginWord = "hit"
endWord = "cog"
wordList = ["hot","dot","dog","lot","log"]1
[]
Intuition
本题要求的是最短转换序列,看到最短首先想到的就是 BFS。想到 BFS 自然而然的就能想到图,但是本题并没有直截了当的给出图的模型,因此我们需要把它抽象成图的模型。
我们可以把每个单词都抽象为一个点,如果两个单词可以只改变一个字母进行转换,那么说明他们之间有一条双向边。因此我们只需要把满足转换条件的点相连,就形成了一张图。根据示例 1 中的输入,我们可以建出下图:
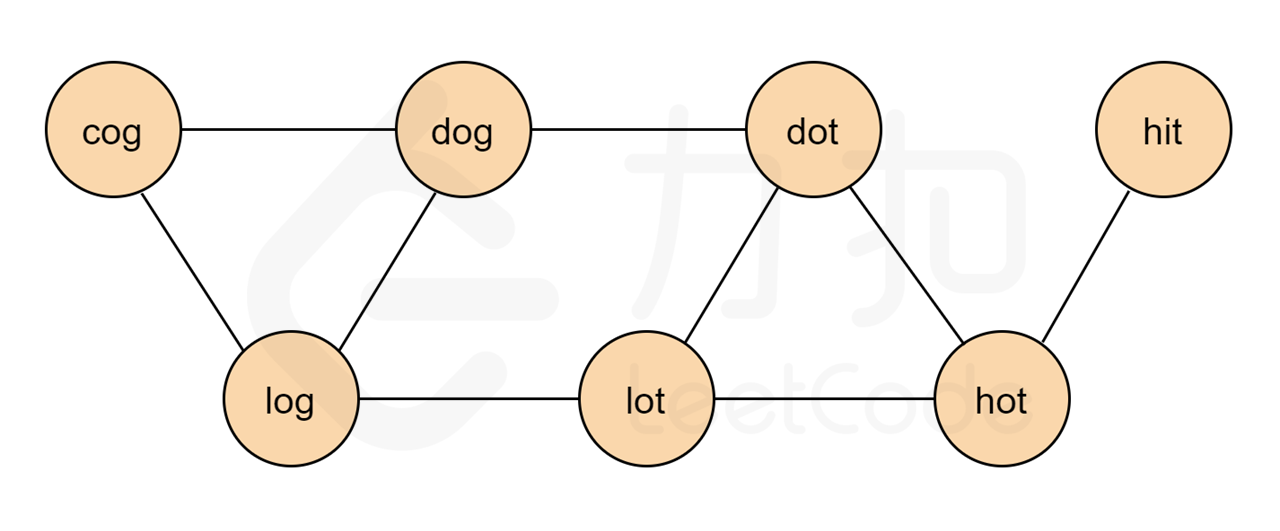
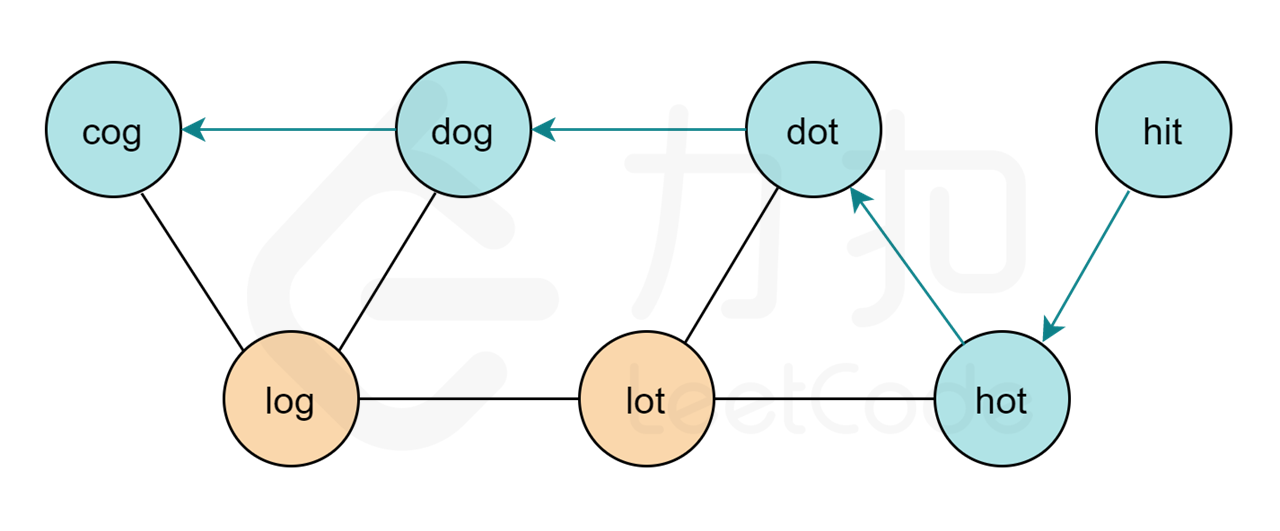
基于该图,我们以 hit 为图的起点, 以cog 为终点进行广度优先搜索(BFS),寻找 hit 到 cog 的最短路径。下图即为答案中的一条路径。
时间复杂度:\(O(N^2 \times C)\)。其中 \(N\) 为 wordList 的长度,\(C\) 为列表中单词的长度。构建映射关系的时间复杂度为 \(O(N)\)。建图首先两层遍历 wordList,复杂度为 \(O(N^2)\),里面比较两个单词是否可以转换的时间复杂度为 \(O(C)\),总的时间复杂度为 \(O(N^2\times C)\)。广度优先搜索的时间复杂度最坏情况下是 \(O(N^2)\),因此总时间复杂度为 \(O(N^2 \times C)\)
空间复杂度:\(O(N^2)\),其中 \(N\) 为 wordList 的大小。数组和哈希表的复杂度都为 \(O(N)\),图 edges 的复杂度最坏为 \(O(N^2)\)。广度优先搜索队列的复杂度最坏情况下,即每两个路径都有很多重叠的节点时,也是 \(O(N^2)\),因此总的空间复杂度为 \(O(N^2)\)。
拓展
由于本题起点和终点固定,所以可以从起点和终点同时开始进行双向广度优先搜索,可以进一步降低时间复杂度。
Code
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!