算法复杂度分析
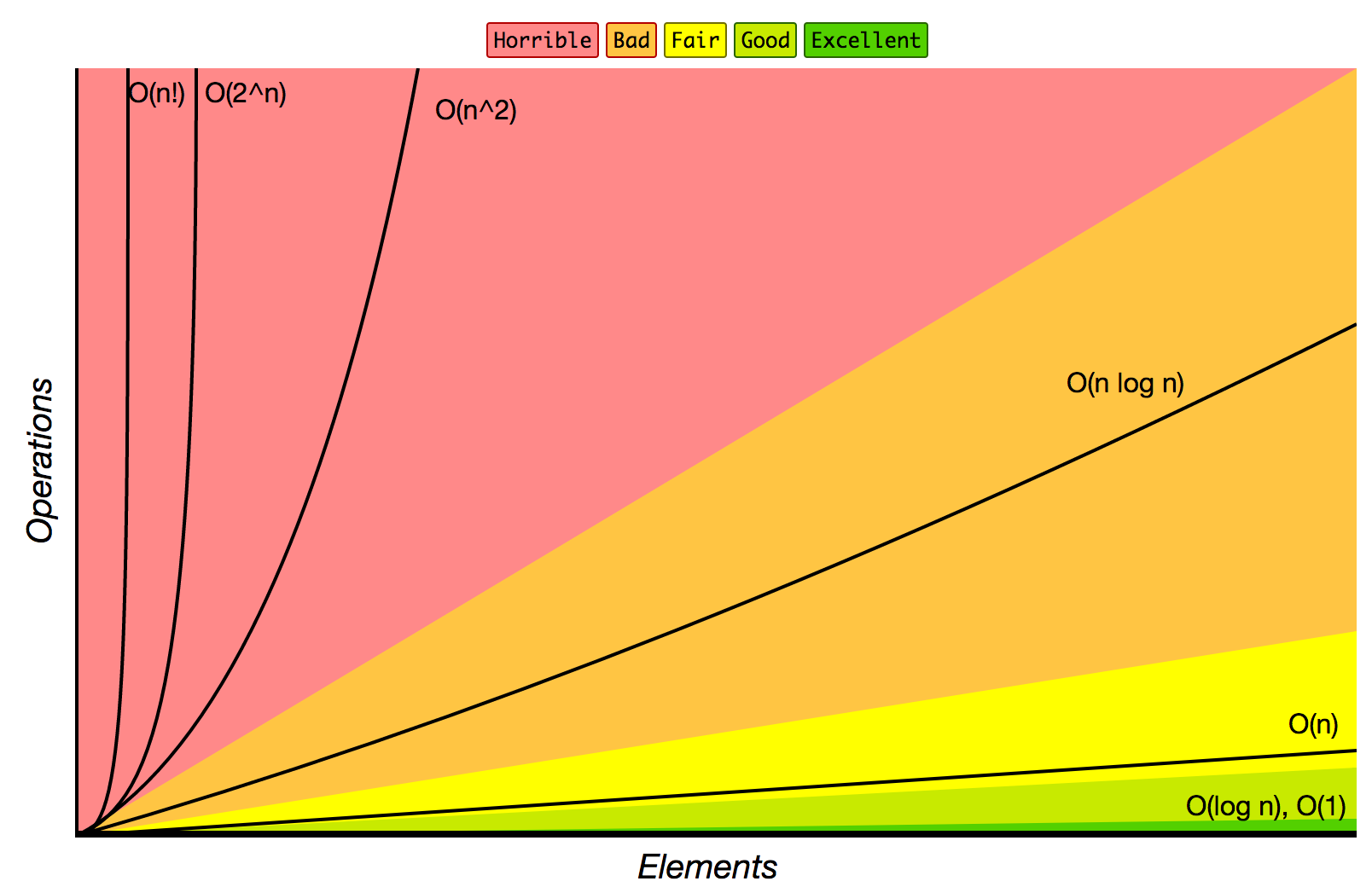
算法的复杂度理论
参考链接
作者:司马懿 链接:https://www.zhihu.com/question/21387264/answer/422323594 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:raymondCaptain 链接:https://www.jianshu.com/p/f4cca5ce055a 来源:简书 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
时间复杂度
常数级别 \(O(1)\)
先从 \(O(1)\) 是指,每次执行该操作只需要恒定的时间,和数据量无关。
理论上哈希表就是 \(O(1)\)。因为哈希表是通过哈希函数来映射的,所以拿到一个关键字,用哈希函数转换一下,就可以直接从表中取出对应的值。
和现存数据有多少毫无关系,故而每次执行该操作只需要恒定的时间(当然,实际操作中存在冲突和冲突解决的机制,不能保证每次取值的时间是完全一样的)。举个现实的例子,比如我的身后有一排柜子,里面有香蕉(代号B),苹果(代号A),葡萄(G),现在你说A,我迅速的就把苹果递过来了;你说B,我迅速就把香蕉递过来了。就算你再增加菠萝(P)、火龙果(H),但是你说一个代号,我递给你相应的水果这个速度是几乎不会变的。
对数级别 \(O(logn)\)
\(O(logn)\) 的算法复杂度,典型的比如二分查找。设想一堆试卷,已经从高到底按照分数排列了,我们现在想找到有没有59分的试卷。怎么办呢?先翻到中间,把试卷堆由中间分成上下两堆,看中间这份是大于还是小于59,如果大于,就留下上面那堆,别的丢掉,如果小于,就留下下面那堆,丢掉上面。然后按照同样的方法,每次丢一半的试卷,直到丢无可丢为止。
假如有32份试卷,你丢一次,还剩16份 ,丢两次,还剩下8 份,丢三次,就只剩下4份了,可以这么一直丢下去,丢到第五次,就只剩下一份了。而 \(log_2(32)=5\) 。也就是我们一次丢一半,总要丢到只有一份的时候才能出结果,如果有 \(n\) 份,那么显然我们就有: \[ \frac{n}{2^k} = 1 \Rightarrow k = log_2n \] 也就是大约需要 \(log_2n\) 次,才能得出 “找到” 或者 “没找到” 的结果。当然你说你三分查找,每次丢三分之二可不可以?当然也可以,但是算法复杂度在这里是忽略常数的,所以不管以2为底,还是以什么数为底,都统一的写成 \(O(logn)\) 的形式。
线性级别 \(O(n)\)
至于 \(O(n)\) ,这个就是说随着样本数量的增加,复杂度也随之线性增加。
典型的比如数数。如果一个人从1数到100,需要100秒,那么从1到200,基本上不会小于200秒,所以数数就是一个 \(O(n)\) 复杂度的事情。一般来说,需要序贯处理的算法的复杂度,都不会低于 \(O(n)\) 。比如说,如果我们要设计一个算法从一堆杂乱的考试的卷子里面找出最高的分数,这就需要我们从头到尾看完每一份试卷,显然试卷越多,需要的时间也越多,这就是一个 \(O(n)\) 复杂度的算法。
线性对数级别 \(O(nlogn)\)
然后是 \(O(nlogn)\) ,分两种情况:
1、这个 \(logn\) 代表该算法中存在一个时间复杂度是 \(O(logn)\)的基础算法,而前面那个 \(n\),代表执行了 \(n\) 次 时间复杂度为\(O(logn)\) 的基础算法。
2、这个 \(n\) 代表该算法中存在一个时间复杂度是 \(O(n)\)的基础算法,而前面那个 \(logn\),代表执行了 \(logn\) 次 时间复杂度为\(O(n)\) 的基础算法。
两种情况下,算法时间复杂度都是 线性对数级别 \(O(nlogn)\)。
快排每次排序都是在进行二分查找,时间复杂度为 \(O(log_2n)\),要完成排序,要对 \(n\) 个元素执行 \(n\) 次二分查找,则快排的时间复杂度为 \(O(nlogn)\)。
理解了这一点,就可以理解快速排序为什么是 \(O(nlogn)\) 了。比如对一堆带有序号的书进行排序,怎么快呢?就是随便先选一本,然后把号码大于这本书的扔右边,小于这本书的扔左边。因为每本书都要比较一次,所以这么搞一次的复杂度是 \(O(n)\) ,那么快排需要我们搞多少次呢?这个又回到了二分查找的逻辑了,每次都把书堆一分为二,请问分多少次手里才能只剩下一本书呢?答案还是 \(logn\) 。而从代码的角度来说,在到达大小为一的数列之前,我们也是需要作 \(logn\) 次嵌套的调用。
平方级别 \(O(n^2)\)
而 \(O(n^2)\) 是说,计算的复杂度随着样本个数的平方数增长。
这个例子在算法里面,就是那一群比较挫的排序,比如冒泡、选择等等。沿着我们刚才的说的那个试卷的例子,等我们找出最高的分数之后,放在一边另起一堆,然后用同样的方法找第二高的分数,再放到新堆上…… 这样我们做n次,试卷就按照分数从低到高都排好了。因为有 \(n\) 份试卷,所以这种翻试卷,找最高分的行为,我们要做 \(n\) 次,每次的复杂度是 \(O(n)\) ,那么n个 \(O(n)\) 自然就是 \(O(n^2)\)。
在比如说构建一个网络,每个点都和其他的点相连。显然,每当我们增加一个点,其实就需要构建这个点和所有现存的点的连线,而现存的点的个数是 \(n\),所以每增加 \(1\),就需要增加 \(n\) 个连接,那么如果我们增加 \(n\) 个点呢,那这个连接的个数自然也就是 \(n^2\) 量级了。
无论是翻试卷,还是创建网络,每增加一份试卷,每增加一个点,都需要给算法执行人带来 \(n\) 量级的工作量,这种算法的复杂度就是 \(O(n^2)\)。
立方级别 \(O(n^3)\)
典型的三层嵌套循环
1 | |
k次方级别 \(O(n^k)\)
k层嵌套循环
1 | |
指数级别 \(O(2^n)\)
求该方法的时间复杂度
1 | |
参考答案: 显然运行次数,\(T(0) = T(1) = 1\),同时 \(T(n) = T(n - 1) + T(n - 2) + 1\),这里的 \(1\) 是其中的加法运算的一次执行。 显然 \(T(n) = T(n - 1) + T(n - 2)\) 是一个斐波那契数列,通过归纳证明法可以证明,当 \(n >= 1\) 时 \(T(n) < (\frac{5}{3})^n\),同时当 \(n > 4\) 时 \(T(n) >= (\frac{3}{2})^n\)。 所以该方法的时间复杂度可以表示为 \(O((\frac{5}{3})^n)\),简化后为 \(O(2^n)\)。 可见这个方法所需的运行时间是以指数的速度增长的。
如果一个算法的运行时间是指数级的(exponential),一般它很难在实践中使用,执行次数:
N=10,大约执行1024次 N=100,大约执行2^100次 N=1000,大约执行2^1000次 N=10000,大约执行2^10000次
空间复杂度
常数级别 \(O(1)\)
只需要几个常数、指针等可数的额外变量。
线性级别 \(O(n)\)
需要一个一维数组或链表,其长度和要处理的数据正向相关。
平方级别 \(O(n^2)\)
需要一个矩阵,其长度和要处理的数据正向相关。
立方级别 \(O(n^3)\)
需要一个三维矩阵,其长度和要处理的数据正向相关。
k次方级别 \(O(n^k)\)
需要一个 \(k\) 维矩阵,其长度和要处理的数据正向相关。
指数级别 \(O(2^n)\)
需要一个大小为 \(2^n\) 的变量,保存变量或处理结果。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!