整理回顾了一下一篇四年前(2016年4月)写的Python爬虫博客 主要内容是当时从崔庆才大佬的网站 上整理出来的 现在时代变了,网站基本上都有了混淆或者一些接口加了很多加密参数 所以后面应该会补上一篇总结 JavaScript 逆向和 App 逆向技术结合Python爬虫解决实际问题的文章
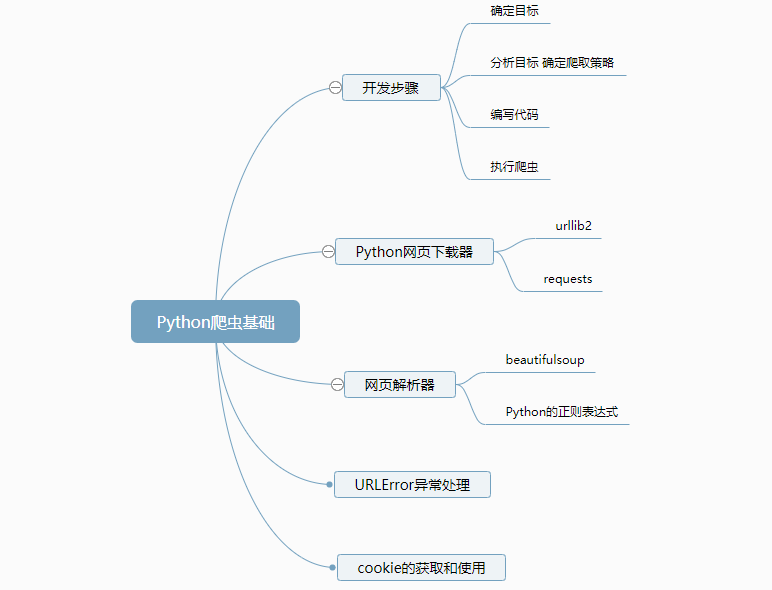
开发爬虫的步骤
确定目标
分析目标,形成抓取策略
编写代码
执行爬虫
Python网页下载器
urllib2:这是Python的官方基础模块 requests:这是一个更强大的第三方包
urllib2的使用方法
将url传入到urllib2.urlopen(url),这样就会直接得到一个网页的数据,这是最简洁的方法。
import urllib2'http://www.baidu.com' )print response.getcode()
添加data、http header
import urllib2'a' ,'1' ) 'User-Agent' ,'Mozilla/5.0' ) 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' 'username' : 'cqc' , 'password' : 'XXXX' } 'User-Agent' : user_agent }
POST和GET数据传送 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 >>> import urllib>>> import urllib2>>> valuse = {'username' :'123@qq.com' ,'password' :'123' }>>> data = urllib.urlencode(valuse) >>> url = "http://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn" >>> request = urllib2.Request(url,data) >>> response = urllib2.urlopen(request) >>> print response.read()>>> values = {}>>> valuse['username' ] = '123@qq.com' >>> valuse['password' ] = '123' >>> data = urllib.urlencode(valuse)>>> url = "http://passport.csdn.net/account/login" >>> geturl = url + '?' + data>>> print geturl>>> request = urllib2.Request(geturl)>>> response = urllib2.urlopen(request)
urlopen(url, data, timeout)
添加特殊的情景处理器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import utllib2, cookielib'''创建1个opener,HTTPCookieProcessor()以cj为参数是一个cookie处理器,生成一个Handler,再将这个Handler传给urllib2的build_opener()函数来生成一个opener对象''' "http://www.baidu.com/" )
对付反盗链
对付”反盗链”的方式,对付防盗链,服务器会识别 headers 中的 referer 是不是它自己,如果不是,有的服务器不会响应,所以我们还可以在headers中加入 referer
>>>headers = {'Referer' : 'http://www.zhihu.com/articles' , 'User-Agent' : 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' }'Referer' : 'http://www.zhihu.com/articles' , 'User-Agent' : 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)' }
urllib2 默认会使用环境变量 http_proxy 来设置 HTTP Proxy。假如一个网站它会检测某一段时间某个IP 的访问次数,如果访问次数过多,它会禁止你的访问。所以你可以设置一些代理服务器来帮助你做工作,每隔一段时间换一个代理,网站君都不知道是谁在访问。 import urllib2True "http" : 'http://some-proxy.com:8080' })if enable_proxy:else :
Timeout 设置 urlopen方法了,第三个参数就是timeout的设置,可以设置等待多久超时,为了解决一些网站实在响应过慢而造成的影响。
import urllib2'http://www.baidu.com' , timeout=10 )'http://www.baidu.com' ,data,10 )
HTTP 的 PUT 和 DELETE 方法 http协议有六种请求方法,get,head,put,delete,post,options,我们有时候需要用到PUT方式或者DELETE方式请求
PUT:这个方法比较少见。HTML表单也不支持这个。本质上来讲, PUT和POST极为相似,都是向服务器发送数据,但它们之间有一个重要区别,PUT通常指定了资源的存放位置,而POST则没有,POST的数据存放位置由服务器自己决定。 DELETE:删除某一个资源。基本上这个也很少见,不过还是有一些地方比如amazon的S3云服务里面就用的这个方法来删除资源。
如果要使用 HTTP PUT 和 DELETE ,只能使用比较低层的 httplib 库。虽然如此,我们还是能通过下面的方式,使 urllib2 能够发出 PUT 或DELETE 的请求,不过用的次数的确是少,在这里提一下。
import urllib2lambda : 'PUT'
使用 Debug Log 可以通过下面的方法把 Debug Log 打开,这样收发包的内容就会在屏幕上打印出来,方便调试,这个也不太常用,仅提一下
import urllib21 )1 )'http://www.baidu.com' )
网页解析器
主要分两个方向: 1、模糊匹配:正则表达式(最后单独介绍) 2、结构化解析:html.parser、Beautiful Soup、lxml,结构化解析—DOM(Document Object Model)树是W3C组织官方定义的解析网页的接口。
beautifulsoup4
在C:,确认pip.exe文件是存在的情况下,pip安装即可。
pip install beautifulsoup4
由 html 网页创建beautifulsoup对象 搜索节点find_all、find: 访问节点名称、属性、文字
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 from bs4 import BeautifulSoup'html.parser' 'utf-8' 'a' )'a' ,herf='/view/123.html' )'a' ,href=re.compile (r'/view/\d+\.html' ))'div' , class_='abc' ,string='Python' )'href' ]
实例源码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 from bs4 import BeautifulSoupimport sysimport retype = sys.getfilesystemencoding()""" <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """ 'html.parser' , from_encoding='utf-8' )print '获取所有的链接' .decode('UTF-8' ).encode(type )'a' )for link in links:print link.name, link['href' ], link.get_text()print '获取lacie的链接' .decode('UTF-8' ).encode(type )'a' , href='http://example.com/lacie' )print link_node.name, link_node['href' ], link_node.get_text()print '正则匹配' .decode('UTF-8' ).encode(type )'a' , href=re.compile (r"ill" ))print link_node.name, link_node['href' ], link_node.get_text()print '获取P段落文字' .decode('UTF-8' ).encode(type )'p' , class_='title' )print p_node.name, p_node.get_text()
Python的正则表达式
regular expression.jpg
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
正则表达式的大致匹配过程是:
依次拿出表达式和文本中的字符比较,
如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。
如果表达式中有量词或边界,这个过程会稍微有一些不同。
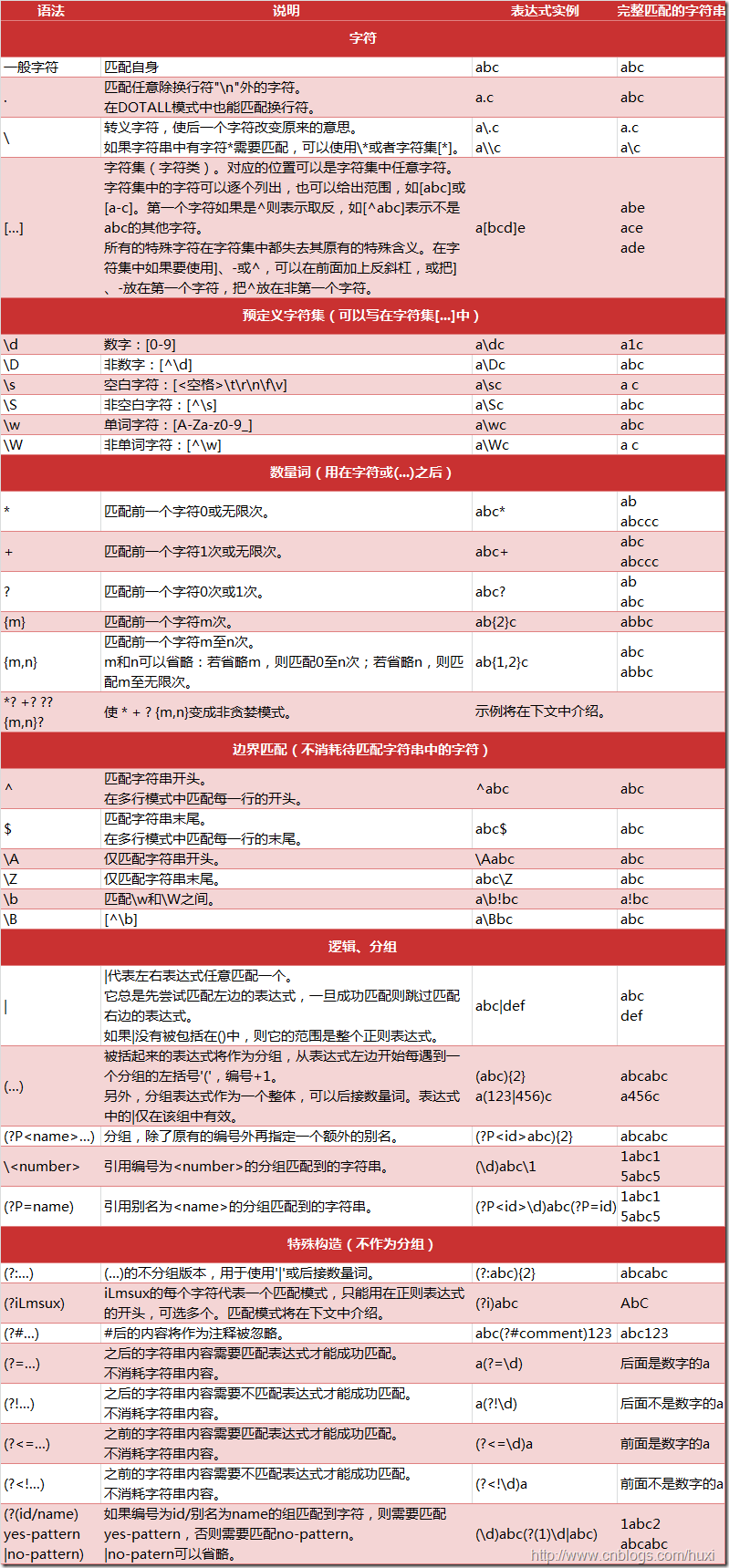
正则表达式相关注解
数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符 ;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:正则表达式 ”ab*” 如果用于查找 ”abbbc”,将找到 ”abbb”。而如果使用非贪婪的数量词”ab*?”,将找到”a”。
注:我们一般使用非贪婪模式来提取。
反斜杠问题
与大多数编程语言相同,正则表达式里使用””作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符””,那么使用编程语言表示的正则表达式里将需要4个反斜杠”\\”:前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r”\”表示 。同样,匹配一个数字的”\d”可以写成r”。有了原生字符串,妈妈也不用担心是不是漏写了反斜杠,写出来的表达式也更直观勒。
Python的re模块
pattern
compile (string[,flag])
pattern可以理解为一个匹配模式 ,利用re.compile方法就可以获得一个pattern,例如:
pattern = re.compile (r'Hello' )
在参数中我们传入了原生字符串对象,通过compile方法编译生成一个pattern对象,然后我们利用这个对象来进行进一步的匹配。re.compile(string[,flag]),另外一个参数flag是匹配模式,取值可以使用按位或运算符’|’表示同时生效,比如re.I | re.M。可选值有:
• re.I(全拼:IGNORECASE): 忽略大小写(括号内是完整写法,下同)'^' 和'$' 的行为(参见上图)'.' 的行为\w \W \b \B \s \S 取决于当前区域设定 \w表示任意字母或数字 \d表示任意数字 \w \W \b \B \s \S \d \D 取决于unicode定义的字符属性
注:以下七个方法中的flags同样是代表匹配模式的意思,如果在pattern生成时已经指明了flags,那么在下面的方法中就不需要传入这个参数了
re.match()
re.match(pattern, string[, flags]), 必须从开头匹]配正则 match匹配必须从目标字符串的开头就开始匹配,如果开头不是目标字符串
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 ''' Created on 2016年4月25日 @author: Tony ''' import recompile (r'helo' )'hello' )'helloo CQC!' )'helo CQC!' )'hello CQC!' )if result1:print result1.group()else :print '1匹配失败!' if result2:print result2.group()else :print '2匹配失败!' if result3:print result3.group()else :print '3匹配失败!' if result4:print result4.group()else :print '4匹配失败!'
运行结果:
match对象的的属性和方法,Match对象是一次匹配的结果,包含了很多关于此次匹配的信息,可以使用Match提供的可读属性或方法来获取这些信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 属性:1. string: 匹配时使用的文本。2. re: 匹配时使用的Pattern对象。3. pos: 文本中正则表达式开始搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。4. endpos: 文本中正则表达式结束搜索的索引。值与Pattern.match()和Pattern.seach()方法的同名参数相同。5. lastindex: 最后一个被捕获的分组在文本中的索引。如果没有被捕获的分组,将为None 。6. lastgroup: 最后一个被捕获的分组的别名。如果这个分组没有别名或者没有被捕获的分组,将为None 。1. group ([group1, …]):0 代表整个匹配的子串;不填写参数时,返回group (0 );没有截获字符串的组返回None ;截获了多次的组返回最后一次截获的子串。2. groups ([default ]):group (1 ,2 ,…last)。default 表示没有截获字符串的组以这个值替代,默认为None 。3. groupdict([default ]):default 含义同上。4. start ([group ]):group 默认值为0 。5. end ([group ]):1 )。group 默认值为0 。6. span([group ]):start (group ), end (group ))。7. expand(template ):template 中然后返回。template 中可以使用\id或\g、\g引用分组,但不能使用编号0 。\id与\g是等价的;但\10 将被认为是第10 个分组,如果你想表达\1 之后是字符’0 ’,只能使用\g0。
举个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 import rer'(\w+) (\w+)(?P<sign>.*)' , 'hello world!' )print "m.string:" , m.stringprint "m.re:" , m.reprint "m.pos:" , m.posprint "m.endpos:" , m.endposprint "m.lastindex:" , m.lastindexprint "m.lastgroup:" , m.lastgroupprint "m.group():" , m.group()print "m.group(1,2):" , m.group(1 , 2 )print "m.groups():" , m.groups()print "m.groupdict():" , m.groupdict()print "m.start(2):" , m.start(2 )print "m.end(2):" , m.end(2 )print "m.span(2):" , m.span(2 )print r"m.expand(r'\g \g\g'):" , m.expand(r'\2 \1\3' )
re.search()
re.search(pattern, string[, flags]),全文搜索正则。 search方法与match方法极其类似,区别在于match()函数只检测re是不是在string的开始位置匹配,search()会扫描整个string查找匹配 ,match()只有在0位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回None。同样,search方法的返回对象同样match()返回对象的方法和属性。我们用一个例子感受一下
import recompile (r'world' )'hello world!' )if match:print match.group()
re.split()
re.split(pattern, string[, maxsplit]) 分割正则 按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。我们通过下面的例子感受一下。
import recompile (r'\s+' ) print re.split(pattern,'one1 tw o2three3fo ur4' )
re.findall()
re.findall(pattern, string[, flags]) 以列表返回所有正则 搜索string,以列表形式返回全部能匹配的子串。我们通过这个例子来感受一下
>>> pattern = re.compile (r'\d+' )>>> print re.findall(pattern,'one1two2three3four4' )'1' , '2' , '3' , '4' ]
re.finditer()
re.finditer(pattern, string[, flags]) 以迭代器返回所有搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。我们通过下面的例子来感受一下
>>> pattern = re.compile (r'\d+' )>>> for m in re.finditer(pattern,'one1two2three3four4' ):print m.group() 1 2 3 4
re.sub()
re.sub(pattern, repl, string[, count]) 替换正则 使用repl替换string中每一个匹配到了的子串后返回替换后的字符串。 当repl是一个字符串时,可以使用 \id 或 \g、\g 引用分组,但不能使用编号0。 当repl是一个方法时,这个方法应当只接受一个参数(Match对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。count用于指定最多替换次数,不指定时全部替换。
>>> import re>>> pattern = re.compile (r'(\w+) (\w+)' ) >>> s = 'i say,hello worlrd!' >>> print re.sub(pattern,r'\2 \1' ,s) >>> def func (m ):>>> print re.sub(pattern,func,s)
re.subn()
re.subn(pattern, repl, string[, count]) 替换并统计次数正则 返回 (sub(repl, string[, count]), 替换次数)。 也就是说,使用subn时,会返回替换的次数。
>>> pattern = re.compile (r'(\w+) (\w+)' ) >>> s = 'i say,hello world' >>> print re.subn(pattern,r'\2 \1' ,s)>>> def funccopy (m ):>>> print re.subn(pattern,funccopy(),s)
Python的模块的另一种使用方法
可以通过 pattern.match,pattern.search 调用,这样调用便不用将 pattern 作为第一个参数传入了,大家想怎样调用皆可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 match(string[, pos[, endpos]]) | re.match(pattern, string[, flags])>>> pattern = re.compile (r'(\w+) (\w+)' )>>> s = 'i say,hello world' >>> print pattern.subn(r'\2 \1' ,s)'say i,world hello' , 2 )>>> pattern = re.compile (r'\d+' )>>> s = 'one1two2three3four4' >>> print pattern.split(s)'one' , 'two' , 'three' , 'four' , '' ]
正则部分的内容整理自了此链接
URLError异常处理
首先解释下URLError可能产生的原因: 1、网络无连接,即本机无法上网 2、连接不到特定的服务器 3、服务器不存在
import urllib2 'http://www.xxdsafasdxx.com/' )try :print response.getcode()except urllib2.URLError as err:print 'Error is ' +str (err)
输出 Error is <urlopen error [Errno 10060] >
HTTPError实例产生后会有一个code属性,这就是是服务器发送的相关错误号。 因为urllib2可以为你处理重定向,也就是3开头的代号可以被处理,并且100-299范围的号码指示成功,所以你只能看到400-599的错误号码。
req = urllib2.Request('http://blog.csdn.net/cqcre' )try :except urllib2.HTTPError, e:print e.codeprint e.reason
输出: 父类的异常应当写到子类异常的后面 ,如果子类捕获不到,那么可以捕获父类的异常,所以上述的代码可以这么改写 import urllib2'http://blog.csdn.net/cqcre' )try :except urllib2.HTTPError, e:print e.codeexcept urllib2.URLError, e:print e.reasonelse :print "OK"
Cookie,指某些网站为了辨别用户身份、进行session跟踪而** **上的数据(通常经过加密)
比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的。那么我们可以利用Urllib2库保存我们登录的Cookie,然后再抓取其他页面就达到目的了。
当你获取一个URL你使用一个opener(一个urllib2.OpenerDirector的实例)。在前面,我们都是使用的默认的opener,也就是urlopen。它是一个特殊的opener,可以理解成opener的一个特殊实例,传入的参数仅仅是url,data,timeout。
如果我们需要用到Cookie,只用这个opener是不能达到目的的,所以我们需要创建更一般的opener来实现对Cookie的设置。
cookielib模块的主要作用是提供可存储cookie的对象,以便于与urllib2模块配合使用来访问Internet资源。Cookielib模块非常强大,我们可以利用本模块的 类的对象来捕获cookie并在后续连接请求时重新发送,比如可以实现模拟登录功能。该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系:CookieJar —-派生—->FiCookieJarleCookieJar —-派生—–>MozillaCookieJar和LWPCookieJar
获取cookie保存到变量
import urllib2import cookielibopen ('http://www.baidu.com' ) for item in cookie:print 'Name = ' +item.nameprint 'Value = ' +item.value
输出 Name = BAIDUIDValue = 3 CDE78 A0 F326492 D542 AE1 C3 FE209 D68 :FG=1 Name = BIDUPSIDValue = 3 CDE78 A0 F326492 D542 AE1 C3 FE209 D68 Name = H_PS_PSSIDValue = 18881 _19719 _1443 _19671 _19721 _19781 _17948 _19803 _19806 _19558 _19808 _18559 _15466 _12397 _10632 Name = PSTMValue = 1461513550 Name = BDSVRTMValue = 0 Name = BD_HOMEValue = 0
使用FileCookieJar的子类MozillaCookieJar来实现Cookie的保存
import urllib2'cookie.txt' open ('http://www.baidu.com' ) True , ignore_expires=True )
关于最后save方法的两个参数在此说明一下: ignore_discard的意思是即使cookies将被丢弃也将它保存下来, ignore_expires的意思是如果在该文件中cookies已经存在,则覆盖原文件写入, 我们将这两个全部设置为True。运行之后,cookies将被保存到cookie.txt文件中。
从文件中获取Cookie并访问
以后要访问一个网站的话,可以从文件中把cookie读取出来再访问网站。
import urllib2'cookie.txt' , ignore_discard=True , ignore_expires=True ) "http://www.baidu.com" ) open (request)print response.read()
一个用cookie模拟登陆的实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import urllibimport urllib2import cookielib'cookie.txt' 'stuid' :'201200131012' ,'pwd' :'23342321' 'http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bks_login2.login' open (loginUrl,postdata) True , ignore_expires=True ) 'http://jwxt.sdu.edu.cn:7890/pls/wwwbks/bkscjcx.curscopre' open (gradeUrl) print result.read()
opener.open方法和urlopen用POST方法比较