Python基础简单整理
整理一下Python的基础和面试常问的问题
Python基础
基本数据类型
数值型
- int:整型,Python对整数没有大小限制,一般java的整型限制在 \(-2^{32}\) 到 \(2^{32} - 1\)。
- float:浮点型
- complex:复数,前两种数值型很常见,这里重点介绍 complex,
complex(real, imag)实际上是一个创建real + imag * j复数的函数。
1 | |
Python数学函数
| 函数 | 返回值 ( 描述 ) |
|---|---|
| abs(x) | 返回数字的绝对值,如abs(-10) 返回 10 |
| ceil(x) | 返回数字的上入整数,如math.ceil(4.1) 返回 5 |
| cmp(x, y) | 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1 |
| exp(x) | 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 |
| fabs(x) | 返回数字的绝对值,如math.fabs(-10) 返回10.0 |
| floor(x) | 返回数字的下舍整数,如math.floor(4.9)返回 4 |
| log(x) | 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 |
| log10(x) | 返回以10为基数的x的对数,如math.log10(100)返回 2.0 |
| max(x1, x2,...) | 返回给定参数的最大值,参数可以为序列。 |
| min(x1, x2,...) | 返回给定参数的最小值,参数可以为序列。 |
| modf(x) | 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 |
| pow(x, y) | x**y 运算后的值。 |
| [round(x ,n]) | 返回浮点数x的四舍五入值,如给出n值,则代表舍入到小数点后的位数。 |
| sqrt(x) | 返回数字x的平方根 |
Python随机数函数
随机数可以用于数学,游戏,安全等领域中,还经常被嵌入到算法中,用以提高算法效率,并提高程序的安全性。Python包含以下常用随机数函数:
| 函数 | 描述 |
|---|---|
| choice(seq) | 从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。 |
| [randrange (start,] stop [,step]) | 从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为 1 |
| random() | 随机生成下一个实数,它在[0,1)范围内。 |
| [seed(x]) | 改变随机数生成器的种子seed。如果你不了解其原理,你不必特别去设定seed,Python会帮你选择seed。 |
| shuffle(lst) | 将序列的所有元素随机排序 |
| uniform(x, y) | 随机生成下一个实数,它在[x,y]范围内。 |
Python三角函数
Python包括以下三角函数:
| 函数 | 描述 |
|---|---|
| acos(x) | 返回x的反余弦弧度值。 |
| asin(x) | 返回x的反正弦弧度值。 |
| atan(x) | 返回x的反正切弧度值。 |
| atan2(y, x) | 返回给定的 X 及 Y 坐标值的反正切值。 |
| cos(x) | 返回x的弧度的余弦值。 |
| hypot(x, y) | 返回欧几里德范数 sqrt(xx + yy)。 |
| sin(x) | 返回的x弧度的正弦值。 |
| tan(x) | 返回x弧度的正切值。 |
| degrees(x) | 将弧度转换为角度,如degrees(math.pi/2) , 返回90.0 |
| radians(x) | 将角度转换为弧度 |
布尔型
布尔值和布尔代数的表示完全一致,Python中用True、False表示布尔值的两种值。
字符串
关于转义,如果字符串里面有很多字符都需要转义,就需要加很多\,为了简化,Python允许用 r'' 表示 '' 内部的字符串默认不转义,可以自己试试:
1 | |
如果字符串内部有很多换行,用 \n 写在一行里不好阅读,为了简化,Python允许用 '''...''' 的格式表示多行内容,可以自己试试:
1 | |
啥是内建方法:类自身就拥有的方法,使用方法是 instance.Operation()。 啥是内建函数:不需要 import,可以直接使用的函数,使用方法是 function()。
常用内建方法
| 方法 | 详述 |
|---|---|
| string.capitalize() | 把字符串的第一个字符大写 |
| string.center(width) | 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
| string.count(str, beg=0, end=len(string)) | 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| string.decode(encoding='UTF-8', errors='strict') | 以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除非 errors 指 定 的 是 'ignore' 或 者'replace' |
| string.encode(encoding='UTF-8', errors='strict') | 以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' |
| string.endswith(obj, beg=0, end=len(string)) | 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
| string.expandtabs(tabsize=8) | 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
| string.find(str, beg=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
| string.format() | 格式化字符串 |
| string.index(str, beg=0, end=len(string)) | 跟find()方法一样,只不过如果str不在 string中会报一个异常. |
| string.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False |
| string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False |
| string.isdecimal() | 如果 string 只包含十进制数字则返回 True 否则返回 False. |
| string.isdigit() | 如果 string 只包含数字则返回 True 否则返回 False. |
| string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| string.isnumeric() | 如果 string 中只包含数字字符,则返回 True,否则返回 False |
| string.isspace() | 如果 string 中只包含空格,则返回 True,否则返回 False. |
| string.istitle() | 如果 string 是标题化的(见 title())则返回 True,否则返回 False |
| string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
| string.lower() | 转换 string 中所有大写字符为小写. |
| string.lstrip() | 截掉 string 左边的空格 |
| string.maketrans(intab, outtab]) | maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| max(str) | 返回字符串 str 中最大的字母。 |
| min(str) | 返回字符串 str 中最小的字母。 |
| string.partition(str) | 有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. |
| string.replace(str1, str2, num=string.count(str1)) | 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
| string.rfind(str, beg=0,end=len(string) ) | 类似于 find()函数,不过是从右边开始查找. |
| string.rindex( str, beg=0,end=len(string)) | 类似于 index(),不过是从右边开始. |
| string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
| string.rpartition(str) | 类似于 partition()函数,不过是从右边开始查找 |
| string.rstrip() | 删除 string 字符串末尾的空格. |
| string.split(str="", num=string.count(str)) | 以 str 为分隔符切片 string,如果 num 有指定值,则仅分隔 num+ 个子字符串 |
| [string.splitlines(keepends]) | 按照行(', '', ')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| string.startswith(obj, beg=0,end=len(string)) | 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. |
| [string.strip(obj]) | 在 string 上执行 lstrip()和 rstrip() |
| string.swapcase() | 翻转 string 中的大小写 |
| string.title() | 返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| string.translate(str, del="") | 根据 str 给出的表(包含 256 个字符)转换 string 的字符,要过滤掉的字符放到 del 参数中 |
| string.upper() | 转换 string 中的小写字母为大写 |
| string.zfill(width) | 返回长度为 width 的字符串,原字符串 string 右对齐,前面填充0 |
集合
set和dict类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在set中,没有重复的key。所以,可以用set去重其他集合对象。set()去重
1 | |
要创建一个set,需要提供一个list作为输入集合:
1 | |
注意,传入的参数[1, 2, 3]是一个list,而显示的{1, 2, 3}只是告诉你这个set内部有1,2,3这3个元素,显示的顺序也不表示set是有序的。。
通过 add(key) 方法可以添加元素到set中,可以重复添加,但不会有效果:
1 | |
通过 remove(key) 方法可以删除元素:
1 | |
set可以看成数学意义上的无序和无重复元素的集合,因此,两个set可以做数学意义上的交集、并集等操作:
1 | |
set 和 dict 的唯一区别仅在于没有存储对应的 value,但是,set 的原理和 dict 一样,所以,同样不可以放入可变对象,因为无法判断两个可变对象是否相等,也就无法保证 set 内部“不会有重复元素”。试试把 list 放入 set ,看看是否会报错。
列表
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
list 可以用来做为 栈和队列直接使用,入栈 append(),出栈 pop(),入栈 append(),出栈 pop(0)。
也可以把元素插入到指定的位置,比如索引号为1的位置:
1 | |
Python列表函数&方法
Python包含以下函数:
| 序号 | 函数 |
|---|---|
| 1 | cmp(list1, list2) 比较两个列表的元素 |
| 2 | len(list) 列表元素个数 |
| 3 | max(list) 返回列表元素最大值 |
| 4 | min(list) 返回列表元素最小值 |
| 5 | list(seq) 将元组转换为列表 |
Python包含以下方法:
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj) 在列表末尾添加新的对象 |
| 2 | list.count(obj) 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) 将对象插入列表 |
| 6 | [list.pop(index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj) 移除列表中某个值的第一个匹配项 |
| 8 | list.reverse() 反向列表中元素 |
| 9 | list.sort(cmp=None, key=None, reverse=False) 对原列表进行排序 |
元祖
另一种有序列表叫元组:tuple。tuple和list非常类似,但是tuple一旦初始化就不能修改。没有append(),insert(),pop() 这样的方法。其他获取元素的方法和list是一样的。
tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向'a',就不能改成指向'b'。当tuple指向一个可变对象(list、set、dict)时,tuple也可以变化。
tuple的陷阱
当你定义一个tuple时,在定义的时候,tuple的元素就必须被确定下来,比如:
1 | |
如果要定义一个空的tuple,可以写成():
1 | |
但是,要定义一个只有1个元素的tuple,如果你这么定义:
1 | |
定义的不是 tuple,是1这个数!这是因为括号()既可以表示tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python规定,这种情况下,按小括号进行计算,计算结果自然是1。
所以,只有1个元素的tuple定义时必须加一个逗号,,来消除歧义:
1 | |
Python在显示只有1个元素的tuple时,也会加一个逗号,,以免你误解成数学计算意义上的括号。
请问以下变量哪些是tuple类型: 1
2
3
4
5a = () # Yes
b = (1) # No
c = [2] # No
d = (3,) # Yes
e = (4,5,6) # Yes
python可迭代对象的解压与压缩?
利用 zip 将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。
1 | |
元组内置函数
Python元组包含了以下内置函数
| 序号 | 方法及描述 |
|---|---|
| 1 | cmp(tuple1, tuple2) 比较两个元组元素。 |
| 2 | len(tuple) 计算元组元素个数。 |
| 3 | max(tuple) 返回元组中元素最大值。 |
| 4 | min(tuple) 返回元组中元素最小值。 |
| 5 | tuple(seq) 将列表转换为元组。 |
字典
Python内置了字典:dict的支持,dict全称dictionary,在其他语言中也称为map,使用键-值(key-value)存储,具有极快的查找速度。
为什么dict查找速度这么快?dict是基于索引实现的,给定一个名字,比如'Michael',dict在内部就可以直接计算出Michael对应的存放成绩的“页码”,也就是95这个数字存放的内存地址,直接取出来,所以速度非常快。
你可以猜到,这种key-value存储方式,在放进去的时候,必须根据key算出value的存放位置,这样,取的时候才能根据key直接拿到value。
通过dict提供的get()方法,如果key不存在,可以返回None,或者自己指定的value:
要删除一个key,用pop(key)方法,对应的value也会从dict中删除。
dict的key必须是不可变对象,所以tuple可以做dict的key,但是list就不能。这是因为dict根据key来计算value的存储位置,如果每次计算相同的key得出的结果不同,那dict内部就完全混乱了。这个通过key计算位置的算法称为哈希算法(Hash)。
Q:遍历字典是否顺序固定?
A:是的,每次输出的顺序是固定的。
Q:遍历字典是否有序
A:Python3.5之前,都是无序的。之后都是有序的。https://legacy.python.org/dev/peps/pep-0468/
内置函数
| 序号 | 函数及描述 |
|---|---|
| 1 | cmp(dict1, dict2) 比较两个字典元素。 |
| 2 | len(dict) 计算字典元素个数,即键的总数。 |
| 3 | str(dict) 输出字典可打印的字符串表示。 |
| 4 | type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 |
| 5 | dict.clear() 删除字典内所有元素 |
| 6 | dict.copy() 返回一个字典的浅复制 |
| 7 | [dict.fromkeys(seq, val]) 创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值 |
| 8 | dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值 |
| 9 | dict.has_key(key) 如果键在字典dict里返回true,否则返回false |
| 10 | dict.items() 以列表返回可遍历的(键, 值) 元组数组 |
| 11 | dict.keys() 以列表返回一个字典所有的键 |
| 12 | dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 13 | dict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 14 | dict.values() 以列表返回字典中的所有值 |
| 15 | [pop(key,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
| 16 | popitem() 返回并删除字典中的最后一对键和值。 |
dict 和 list 比较
dict有以下几个特点:
- 查找和插入的速度极快,不会随着key的增加而变慢;
- 需要占用大量的内存,内存浪费多。
而list相反:
- 查找和插入的时间随着元素的增加而增加;
- 占用空间小,浪费内存很少。
所以,dict是用空间来换取时间的一种方法。
列表(list)和元祖(tuple)的区别
- 元组内容是不可变的, 而列表内容是可变的。所以,元祖是不可变对象,列表是可变对象。
- 因为元祖不可变的,所以元祖无法复制,但是可以添加一个新的引用。
- 使用方括号
[]创建列表,而使用括号()创建元组。 - 从用途上来说,元组通常由不同的数据,而列表是相同类型的数据队列。本质上讲,元组表示的是结构,而列表表示的是顺序。
- 不能将列表当作字典或集合的key, 而元组可以。
1 | |
由于元组支持的操作比列表小, 所以元组会比列表稍稍快上那么一丢丢。但是除非你有巨量的数据要去处理,否者这一点不需要特别强调。为啥元祖比列表更快,有以几个原因:
1). tuple中是不可变的,在CPython中tuple被存储在一块固定连续的内存中,创建tuple的时候只需要一次性分配内存。但是List被的被存储在两块内存中,一块内存固定大小,记录着Python Object(某个list对象)的信息,另一块是不固定大小的内存,用来存储数据。所以,查找时tuple可以快速定位(C中的数组);list必须遍历(C中的链表)。在编译中,由于Tuple是不可变的,python编译器将它存储在它所在的函数或者模块的“常量表”(constants table)中。运行时,只要找到这些预构建的常量元组。但是List是可变的,必须在运行中构建,分配内存。 2). 当Tuple的元素是List的时候,它只存储list的引用,(C中定长数组里一个元素是指向某个链表的指针),定位查找时它还是会比List快。 3). CPython中已经做了相关优化以减少内存分配次数:释放一个List对象的时候,它的内存会被保存在一个自由List中以重复使用。不过非空list的创建时,仍然需要给它分配内存存储数据。
变量、常量和对象
基本概念
变量
变量存储在内存中的值,这就意味着在创建变量时会在内存中开辟一个空间。 变量本身类型不固定的语言称之为动态语言,与之对应的是静态语言。静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错。
常量
常量就是不能变的变量,也是存储在内存中的值,不过不能变化。比如常用的数学常数π就是一个常量。在Python中,通常用全部大写的变量名表示常量:
1 | |
但事实上PI仍然是一个变量,Python根本没有任何机制保证PI不会被改变 ,所以,用全部大写的变量名表示常量只是一个习惯上的用法,如果你一定要改变变量PI的值,也没人能拦住你。
对象
所谓对象就是指通过类定义的数据结构实例。python中的对象都会有三个特征:
- 身份,即是存储地址,可以通过id()函数来查询。
- 类型,即对象所属的类型,可以用type()函数来查询。
- 值,都会有各自的数据,由魔法函数
__str__决定,默认会输出引用的对象。
Python中一切皆对象,函数是对象,就连创建对象的类也是对象。
1 | |
代码,函数,类,方法,都是对象,但是函数和类相对来说比较高级,属于Python的一等公民,具有如下特性:
- 能够直接赋值给一个变量
- 可以添加到集合对象中
- 能作为函数参数进行传递
- 可以作为函数返回值
仔细想一想,python中是的确是一切皆对象,因为都符合以上条件,属于一等公民对象。
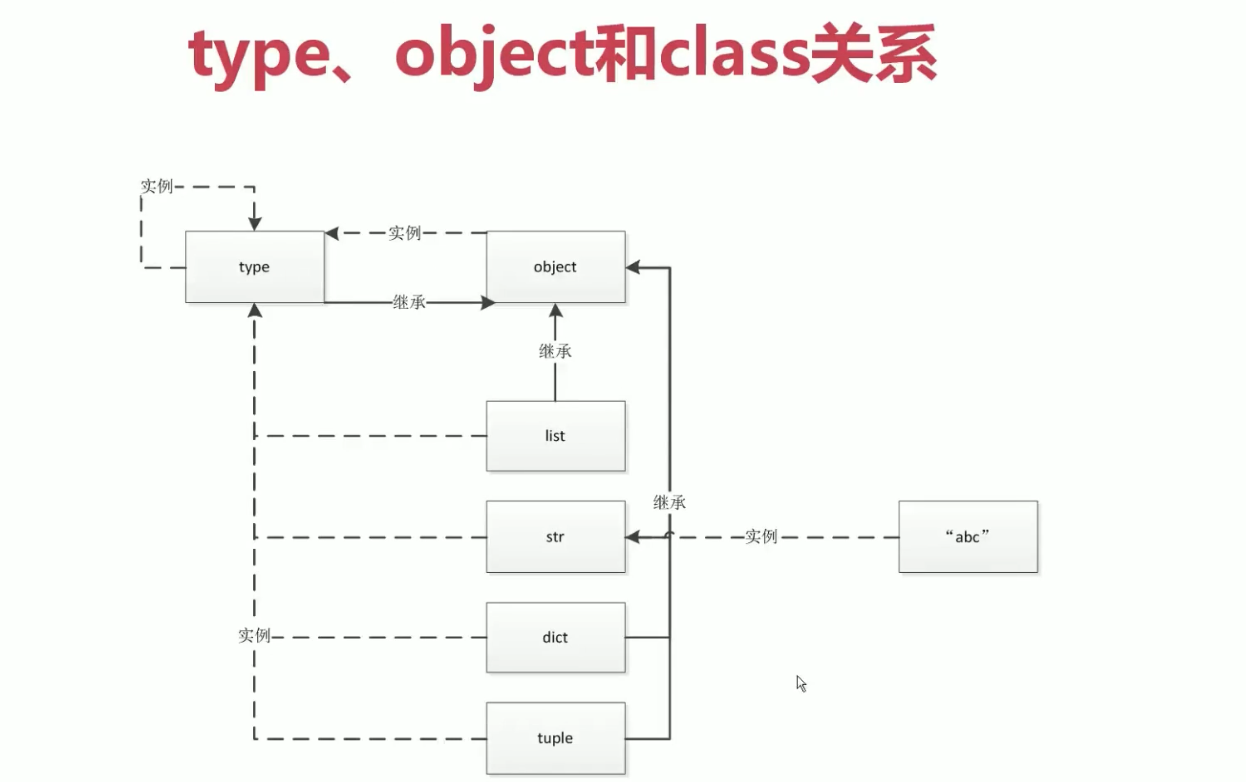
type,object和class的关系()?
- object:有两层含义
- 1、泛指所有对象。
- 2、特指Python中的一个基类,Python中所有类都继承自 object。
- type:有三层含义
- 1、type是一种类型,object(含义二)是的类型就是type,而object(含义二)又是所有类的基类,所以所有 class 的类型都是type。
1
2>>> print(type(object))
<class 'type'> - 2、type也是自己的一个对象(实例)用于返回类型,说到这里,你可能不相信,不过我们下面会有验证。type,一个连自己都不肯放过的类,都要自己实现自己的对象的类。
1
2>>> print(type(type))
<class 'type'> - 3、其他的类都是通过type来生成的,所以类型都是 type。
1
2
3
4
5
6>>> type(int)
<class 'type'>
>>> type(float)
<class 'type'>
>>> type(list)
<class 'type'>
- 1、type是一种类型,object(含义二)是的类型就是type,而object(含义二)又是所有类的基类,所以所有 class 的类型都是type。
- class:Python中的class,又称类,就和我们常见的面向对象编程中的概念一样,是用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。而对象是类的实例。
这里更加充分说明python中一切皆对象的本质。那么,已知,类是通过type来生成的,对象是通过类来生成的,type,object(含义一)和class的关系如下,type 是 class的父层,class是object(含义一)的父层: \[ type \rightarrow class \rightarrow obeject \] 下面用代码来看看
1 | |
type有两种功能,一个是返回一个对象的类型,另一个是生成一个类,所以type、object就是python世界的亚当和夏娃。
Python运行时变量如何保存?
1 | |
当读取到这行代码编译成的字节码文件时,Python解释器干了两件事情:
- 在内存中创造了一个名为
ABC的字符串。 - 在内存中创造了一个名为
a的变量,并把它指向'ABC'。
Python中的可变对象和不可变对象?
python中一切的传递都是引用(地址)传递,无论是赋值还是函数调用时的参数传递,不存在值传递。
python变量保存的是对象的引用,这个引用指向堆内存里的对象。 在堆中分配的对象分为两类,一类是可变对象,一类是不可变对象。
不可变对象的内容不可改变,复制或者参数传递时开辟新空间(元组除外,由于元祖无法修改,就不能再原来的基础上做任何变化,要赋值或者参数传递,直接用同一个引用就行)。保证了数据的不可修改(安全,防止出错),同时可以使得在多线程读取的时候不需要加锁。
数值类型(int、float和complex),字符串str,元组tuple都是不可变对象。
1
2
3
4
5
6
7
8
9a = 1
print id(a) # 40133000L,整数1放在了地址为40133000L的内存中,a变量指向这个地址。
a += 1
print id(a) # 40132976L,整数int不可改变,开辟新空间存放加1后的int,a指向这个新空间。
a = (1, 2)
id(a) # 1786769196992
b = a
id(b) # 1786769196992 不开辟新空间可变对象,变量指向的内存的中的值能够被改变,复制时添加引用,不开辟新空间,多线程读取的时候需要加锁。
列表list,字典dict,集合set都是可变对象。
1
2
3
4
5
6
7
8a = [1,2,3]
print id(a) # 44186120L。
a += [4,5] # 相当于调用了a.extend([4])
print id(a) # 44186120L,列表list可改变,直接改变指向的内存中的值,没开辟新空间。
a = a + [7,8] # 直接+和+=并不等价,使用+来操作list时,得到的是新的list,不指向原空间。
print id(a) # 44210632L参考连接
Python 面向对象 Python一切皆对象 浅谈python中一切皆对象
基本的运算
加减乘除和取余
python的加减乘除和取余,都是很常规的操作。 唯一要注意的是Python的整除 // 都是向下取整的。
1 | |
位运算
关于Python的位运算,参看专题 算法:位运算。
函数和方法
首先,从分类的角度来分析。
函数的分类 1. 内置函数:python内嵌的一些函数。 2. 匿名函数:一行代码实现一个函数功能。 3. 递归函数。 4. 自定义函数:根据自己的需求,来进行定义函数。
方法的分类 1. 普通方法:直接用self调用的方法。 2. 私有方法:__函数名__,只能在类中被调用的方法。 3. 属性方法:@property,将方法伪装成为属性,让代码看起来更合理。 4. 特殊方法(双下划线方法):以__init__为例,是用来封装实例化对象的属性,**只要是实例化对象就一定会执行__init方法**,如果对象子类中没有则会寻找父类(超类),如果父类(超类)也没有,则直接继承object(python 3.x)类,执行类中的__init__方法。 5. 类方法:通过类名的调用去操作公共模板中的属性和方法。 6. 静态方法:不用传入类空间、对象的方法, 作用是保证代码的一致性,规范性,可以完全独立类外的一个方法,但是为了代码的一致性统一的放到某个模块(py文件)中。
其次,从作用域的角度来分析:
- 函数作用域:从函数调用开始至函数执行完成,返回给调用者后,在执行过程中开辟的空间会自动释放,也就是说函数执行完成后,函数体内部通过赋值等方式修改变量的值不会保留,会随着返回给调用者后,开辟的空间会自动释放。
- 方法作用域:通过实例化的对象进行方法的调用,调用后开辟的空间不会释放,也就是说调用方法中对变量的修改值会一直保留,直到对象被销毁?。
最后,调用的方式的角度来分析:
- 函数:通过“函数名()”的方式进行调用。
- 方法:通过“对象.方法名”的方式进行调用。
1 | |
参考链接
面试常见问题
Python的列表解析式
从1-100中选出所有奇数
1 | |
这行代码和上面那有什么区别?
1 | |
上面那个是列表解析式,返回的是一个列表。这行代码是生成器解析式,返回的是一个可迭代对象
1 | |
或者,从1-100中选出所有的素数
1 | |
Python的装饰器
Python中的闭包函数
返回函数(闭包) 谈谈自己的理解:python中闭包,闭包的实质
Python变量的作用域(LEGB原则)
Python 中,程序的变量并不是在哪个位置都可以访问的,访问权限决定于这个变量是在哪里赋值的。变量的作用域决定了在哪一部分程序可以访问哪个特定的变量名称。Python的作用域一共有4种,分别是:
- L (Local) 局部作用域,即函数中定义的变量。
- E (Enclosing) 闭包函数外的函数中,嵌套的父级函数的局部作用域,即包含此函数的上级函数的局部作用域,但不是全局的;
- G (Global) 全局作用域,就是模块级别定义的变量;
- B (Built-in) 内建作用域,系统固定模块里面的变量,比如:int,bytearray等。
以 Local –> Enclosing –> Global –>Built-in 的规则查找,即:在局部找不到,便会去局部外的局部找(例如闭包),再找不到就会去全局找,再者去内建中找。
什么时候会创建新的作用域?
Python 中只有模块(module),类(class)以及函数(def、lambda)才会引入新的作用域,其它的代码块(如 if/elif/else/、try/except、for/while等)是不会引入新的作用域的,也就是说这这些语句内定义的变量,外部也可以访问:
1 | |
global
关键字 global ,使用到的全局变量只是作为引用,在函数中修改它的值的话,需要加 global 关键字。
1 | |
nonlocal
关键字 nonlocal,用于闭包中,nonlocal 就是在闭包中怎样对上一层函数内的变量进行更改。(nonlocal是Python3的新特性)
1 | |
可以看到,闭包内没有 x 会先调用外层 def 的 x,而不是模块中的全局变量 x。故结果为 100。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26# 不加nonlocal
x = 123
def outer():
x = 100
def inter():
x = x + 1 # 这一行会报错 Using variable 'x' before assignment
print(x)
return inter()
outer()
# 加nonlocal
x = 123
def outer():
x = 100
def inner():
nonlocal x
x = x + 1
inner()
print("inner x is {}".format(x))
outer()
print("outer x is {}".format(x))
# output
inner x is 101
outer x is 123nonlocal,更改了外层 def 定义的 x,故结果变为 101,但是全局变量没有更改,仍为 123。
locals()
locals() 会以字典类型返回当前位置的全部局部变量。
1 | |
名规范建议建议: 全局变量全部大写,局部变量全部小写。 不要用内建函数和关键字作变量/函数名。
深拷贝(deepcopy)和浅拷贝(copy)的区别
Python中对象之间的赋值是按引用传递的,如果要拷贝对象需要使用标准模板中的copy - copy.copy:浅拷贝,只拷贝父对象,不拷贝父对象的子对象。 - copy.deepcopy:深拷贝,拷贝父对象和子对象。
The difference between shallow and deep copying is only relevant for compound objects (objects that contain other objects, like lists orclass instances).A shallow copy constructs a new compound object and then (to theextent possible) inserts the same objects into it that theoriginal contains.A deep copy constructs a new compound object and then, recursively,inserts copies into it of the objects found in the original.
浅拷贝构造一个新的复合对象,然后递归地将原来包含的对象的引用插入其中。 深拷贝构造一个新的复合对象,然后递归地将原来包含的对象的副本插入其中。 一般深拷贝比浅拷贝复制得更加完全,但也更占资源(包括时间和空间资源)。 浅层复制和深层复制之间的区别只适用于复合对象(包含其他对象的对象,如列表或类实例)。
1 | |
python2和python3的一些区别
1、Python3 使用 print 必须要以小括号包裹打印内容,比如 print('hi')。 Python2 既可以使用带小括号的方式,也可以使用一个空格来分隔打印内容,比 如 print 'hi'。 2、python2 range(1,10)返回列表,python3中返回迭代器,节约内存。 3、python2中使用ascii编码,python中使用utf-8编码。 4、python2中unicode表示字符串序列,str表示字节序列,python3中str表示字符串序列,byte表示字节序列。 5、python2中为正常显示中文,引入coding声明,python3中不需要。 6、python2中是raw_input()函数,python3中是input()函数。 7、nonlocal是Python3的新特性。
Python的面向对象编程
python类怎么定义静态方法?怎么使用?
Python抽象类
还有类的使用、继承、__init__和__new__的区别,实例方法、类方法、静态方法,实例属性、类属性等等。不一一展开了。
Python里lambda函数
python的 is 和 == 的区别?
简单点讲: 1、Python中对象包含的三个基本要素,分别是:id(身份标识)、type(数据类型)和value(值)。 2、== 是python标准操作符中的比较操作符,用来比较判断两个对象的value是否相等。 3、is 也被叫做同一性运算符,这个运算符比较判断的是对象间的唯一身份标识,也就是id是否相同
1 | |
python内存管理?
- Python内存由Python私有堆空间管理。所有Python对象和数据结构都位于私有堆中。程序员无权访问此私有堆,解释器负责处理此私有堆。
- Python对象的Python堆空间分配由Python内存管理器完成。核心API提供了一些程序员编写代码的工具。
- Python还有一个内置的垃圾收集器,它可以回收所有未使用的内存并释放内存并使其可用于堆空间。
- Python垃圾回收机制详解
cls和self含义
python中cls代表的是类对象的本身,相对应的self则是类的一个具体实例对象。 cls是类方法的参数。 self是实例方法的参数。 关于类方法、实例方法、静态方法参看 Python类方法、类属性、静态方法。
1 | |
__new__ 和 __init__ 的区别
- __init__为初始化方法,__new__方法是真正的构造函数。类对象先调用__new__方法,返回该类的实例对象,这个实例对象就是__init__方法的第一个参数self,即self是__new__的返回值。然后实例对象再调用__init__方法初始化。
- 简单来说,创建一个新实例的时候调用 __new__,初始化一个实例用 __init__。
- __new__是实例创建之前被调用,它的任务是创建并返回该实例,是静态方法。
- __init__是实例创建之后被调用的,然后设置对象属性的一些初始值,是实例方法。
- 由于__new__ 是静态方法,所以无需参数。而 __init__ 是实例方法,所以第一个参数必须是self。
python的生成器和迭代器
总结
- 可迭代对象:可作用于for循环的对象叫可迭代对象,专业角度来说, 内部含有__iter__方法的对象,就是可迭代对象。
next()函数记住遍历位置,不断从前往后访问。- 可以被
next()函数调用而不断返回下一个值的可迭代对象称为迭代器:Iterator。 - 在Python中,具有一边循环迭代一边计算机制的迭代器
Iterator,称为生成器:generator。 generator本质上就是一种特殊的iterator,允许一边迭代一边计算。
关系图
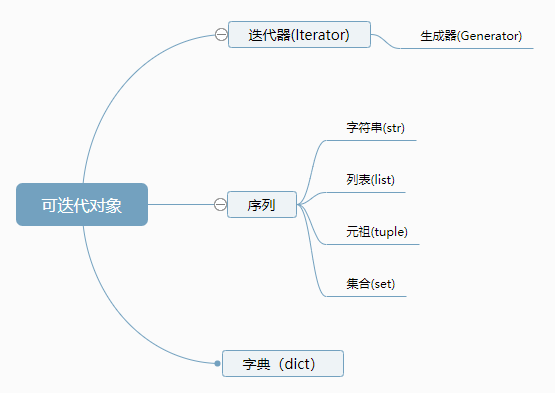
- 可迭代对象需要实现__iter__方法
- 迭代器不仅要实现__iter__方法,还需要实现__next__方法
- 生成器除了要实现__iter__和__next__,还要设计计算机制。
- 自定义 __iter__ 方法和 __next__ 方法
1 | |
Iterator
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。 把range、list、dict、str 等 Iterable 变成Iterator 可以使用 iter()函数:
1 | |
Python的iterator是一个惰性序列,意思是表达式和变量绑定后不会立即进行求值,而是当你用到其中某些元素的时候才去求某元素对的值。 惰性是指,你不主动去遍历它,就不会计算其中元素的值。
Generator
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表, 不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个 generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个 generator:
1 | |
我们可以直接打印出 list 的每一个元素,但我们怎么打印出 generator 的每一个元素呢?
如果要一个一个打印出来,可以通过next()函数获得 generator 的下一个返回值。generator 保存的是算法,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。
当然,上面这种不断调用next(g)实在是太变态了,正确的方法是使用for循环,因为 generator 也是可迭代对象:
1 | |
定义 generator 的另一种方法:如果一个函数定义中包含 yield 关键字,那么这个函数就不再是一个普通函数,而是一个 generator。
1 | |
利用 map 函数也可以创建一个 generator 。
1 | |
可迭代对象 Iterable Object
我们已经知道,可以直接作用于for循环的数据类型有以下几种:
- 一类是集合数据类型,如
list、tuple、dict、set、str等; - 一类是
generator,包括生成器和带yield的 generator function。 - 这些可以直接作用于
for循环的对象统称为可迭代对象:Iterable。 - 可以使用
isinstance()判断一个对象是否是Iterable对象:
1 | |
而生成器不但可以作用于 for 循环,还可以被 next()函数不断调用并返回下一个值,直到最后抛出StopIteration 错误表示无法继续返回下一个值了。
一堆有关函数和表达式的写输出
涉及到各种嵌套使用,类内初始化类本身并赋值,全局变量局部变量)
Python的网络编程了解不
socket编程
如何限制Socket的最大连接数设定一个集合和count变量这个集合用什么数据结构比较好
GIL锁出现的原因
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple native threads from executing Python bytecodes at once. This lock is necessary mainly because CPython’s memory management is not thread-safe. (However, since the GIL exists, other features have grown to depend on the guarantees that it enforces.)
在CPython中,全局解释器锁(GIL)是一个互斥锁,它阻止多个本机线程同时执行Python字节码。这个锁是必需的,主要是因为CPython的内存管理不是线程安全的。(然而,自从GIL存在以来,其他特性已经逐渐依赖于它所实施的保证。)
历史原因,python作者当时就没有多核cpu
没钱,不能像java那样做优化
multiprocessing库做的太好了
为什么会有GIL 由于物理上得限制,各CPU厂商在核心频率上的比赛已经被多核所取代。为了更有效的利用多核处理器的性能,就出现了多线程的编程方式,而随之带来的就是线程间数据一致性和状态同步的困难。即使在CPU内部的Cache也不例外,为了有效解决多份缓存之间的数据同步时各厂商花费了不少心思,也不可避免的带来了一定的性能损失。
Python当然也逃不开,为了利用多核,Python开始支持多线程。而解决多线程之间数据完整性和状态同步的最简单方法自然就是加锁。 于是有了GIL这把超级大锁,而当越来越多的代码库开发者接受了这种设定后,他们开始大量依赖这种特性(即默认python内部对象是thread-safe的,无需在实现时考虑额外的内存锁和同步操作)。
慢慢的这种实现方式被发现是蛋疼且低效的。但当大家试图去拆分和去除GIL的时候,发现大量库代码开发者已经重度依赖GIL而非常难以去除了。有多难?做个类比,像MySQL这样的“小项目”为了把Buffer Pool Mutex这把大锁拆分成各个小锁也花了从5.5到5.6再到5.7多个大版为期近5年的时间,并且仍在继续。MySQL这个背后有公司支持且有固定开发团队的产品走的如此艰难,那又更何况Python这样核心开发和代码贡献者高度社区化的团队呢?
所以简单的说GIL的存在更多的是历史原因。如果推到重来,多线程的问题依然还是要面对,但是至少会比目前GIL这种方式会更优雅。
作者:luikore 链接:https://www.zhihu.com/question/323812020/answer/679515735 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
一是部分诟病的人所碰到的性能问题,真正原因并不是 GIL。他们不知道,或者知道但只需要一个可以甩锅的点。这些人不会正确 benchmark 也不了解实现,自然没有能力去改。另一部分批评的人是为了推广自家语言或者彰显优越感,这些人没有动力去改。
二是改起来太费劲。参考 Java 的实现,虚拟机里要管理很多细粒度的锁才能保证正确性,改得不好单线程的性能要大打折扣。有能力改的人要么认为这根本不需要改,要么没精力改。
pypy 也说了:
Yes, PyPy has a GIL. Removing the GIL is very hard. On top of CPython, you have two problems: (1) GC, in this case reference counting; (2) the whole Python language. For PyPy, the hard issue is (2): by that I mean issues like what occurs if a mutable object is changed from one thread and read from another concurrently. This is a problem for any mutable type: it needs careful review and fixes (fine-grained locks, mostly) through the whole Python interpreter. It is a major effort, although not completely impossible, as Jython/IronPython showed. This includes subtle decisions about whether some effects are ok or not for the user (i.e. the Python programmer). CPython has additionally the problem (1) of reference counting. With PyPy, this sub-problem is simpler: we need to make our GC multithread-aware. This is easier to do efficiently in PyPy than in CPython. It doesn’t solve the issue (2), though. Note that since 2012 there is work going on on a still very experimental Software Transactional Memory (STM) version of PyPy. This should give an alternative PyPy which works without a GIL, while at the same time continuing to give the Python programmer the complete illusion of having one. This work is currently a bit stalled because of its own technical difficulties.
有一个捷径是用软件事务内存,保留 GIL 的代码,但如果没有同时写同一块内存就不是真的锁定。
后来有硬件事务内存,效率想当然是比软件事务内存高的,参见 https://sabi.net/nriley/pubs/dls6-riley.pdf 。
Ruby 的尝试 http://rubykaigi.org/2014/presentation/S-ReiOdaira/ 据说效果很好。
x86 也有 TSX 扩展,但这些尝试能否实用到 x86 的处理器就很难说了。
好了就算你用 HTM 减少了锁的工作量,还有大量语言设计上的问题,这些矛盾和取舍不是几个人发篇文章就能搞得定的。
RESTful API 设计指南
http://www.ruanyifeng.com/blog/2014/05/restful_api.html
工厂模式的三种
pass语句的作用
Python文件对象的权限:r/w/a/x/a+/r+/w+ 的区别
简单来说,r是读,w是写,a是追加写,x也是写模式,a+是可读可写,r+也 是可读可写,w+也是可读可写。 [r+] 如果是先读后写的话是在原有文本后添加,因为读完后类指针已经在最末尾了,如果是先写后读的话,是从头开始覆盖式写(如只修改了前面的字符,后面字符是不会被删掉的),类指针停留在写完的末尾,不是文档末尾,可以读出未被覆盖写的部分; [w+] 为先写后读,先写完后使用 f.seek(0) 回到初始位置然后开始读,如果先读的话是读不出任何东西的,因为w+也是纯粹的覆盖写,在未使用写操作前文档是完全空白的,无论之前该文件里有什么。故,只能先写后读。 [a+] 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 [r / a / w / x] r要求必须已经存在这个文件了而a、w、x则要求文件可以有也可以没有。如果没有原文件,a、w和x都会创建一个。如果有原文件,a会在其后追加、w会覆盖,x会报错。 参考连接:https://www.runoob.com/python/file-methods.html
*arg 和 **kwargs的区别
这里实际上是想问面试者的Python参数传递机制
两种基本的参数传递方法
Python的参数传递机制有两种基本机制:
- 值传递(int、float等不可变对象),值传递,应用的参数不发生更改。(传了个副本进去)
- 引用传递(以字典、列表等可变对象),引用传递,引用的参数发生更改(传的是真实的地址)。
1 | |
python中一切的传递都是引用(地址)传递,无论是赋值还是函数/方法调用时的参数传递,不存在值传递。
- 之所以看起来有值传递,是因为传入的是不可变对象,传入前会开辟了一个新的内存空间赋值该不可变对象的值进行保存并为其设置一个引用,之后的传入的就是这新开辟的内存空间的引用。所以看起来像是进行的值传递。
- 但是,如果传入的是可变对象,就不存在开辟新的内存空间这一说法了,直接就是将这个要传入的可变对象的引用作为参数传入了函数/方法中。
包裹方式的参数传递
python中还允许包裹方式的参数传递,这为不确定参数个数和参数类型的函数调用提供了基础:
python中还允许包裹方式的参数传递,这为不确定参数个数和参数类型的函数调用提供了基础:
知识点:
- 在函数调用时,*会以单个元素的形式解包一个元祖,使其成为独立的参数。
- 在函数调用时,**会以键/值对的形式解包一个字典,使其成为独立的关键字参数。
1 | |
其他解释
解释一
如果我们不确定往一个函数中传入多少参数,或者我们希望以元组(tuple)或者列表(list)的形式传参数的时候,我们可以使用*args(单星号)。
如果我们不知道往函数中传递多少个关键词参数或者想传入字典的值作为关键词参数的时候我们可以使用**kwargs(双星号),args、kwargs两个标识符是约定俗成的用法。
解释二
当函数的参数前面有一个星号*号的时候表示这是一个可变的位置参数,两个星号**表示这是一个可变的关键词参数
Python3 assert(断言)
Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。 断言可以在条件不满足程序运行的情况下直接返回错误,而不必等待程序运行后出现崩溃的情况,例如我们的代码只能在 Linux 系统下运行,可以先判断当前系统是否符合条件。 例如,对输入数据进行格式判断,不符合要求的抛出异常。 1
2
3
4try:
assert type(info)==dict
except:
return "info structure is not correct"
python运维
python查看进程使用内存信息 psutil
1 | |
python查看进程
1 | |
如何在Python里调用shell命令
os.system('ls -l')os.popen('ls -l')cammands.getstatusoutput('ls -l')subprocess.run()
方法一、使用os模块的system方法:os.system(cmd),其返回值是shell指令运行后返回的状态码,int类型,0表示shell指令成功执行,256表示未找到,该方法适用于shell命令不需要输出内容的场景。
1 | |
方法二、使用os.popen(),该方法以文件的形式返回shell指令运行后的结果,需要获取内容时可使用 read() 或readlines() 方法,举例如下:
1 | |
方法三、使用commands模块(该方法Python3已经失效了),有三个方法可以使用:
commands.getstatusoutput(cmd),其以字符串的形式返回的是输出结果和状态码,即(status,output)。commands.getoutput(cmd),返回cmd的输出结果。commands.getstatus(file),返回ls -l file的执行结果字符串,调用了getoutput,不建议使用此方法。
1 | |
方法四、subprocess模块(该方法为Python3推荐方法),允许创建很多子进程,创建的时候能指定子进程和子进程的输入、输出、错误输出管道,执行后能获取输出结果和执行状态。
subprocess.run():python3.5中新增的函数, 执行指定的命令, 等待命令执行完成后返回一个包含执行结果的CompletedProcess类的实例。1
subprocess.run(args, *, stdin=None, input=None, stdout=None, stderr=None, shell=False, timeout=None, check=False, universal_newlines=False)subprocess.call():执行指定的命令, 返回命令执行状态, 功能类似os.system(cmd)。1
subprocess.call(args, *, stdin=None, stdout=None, stderr=None, shell=False, timeout=None)subprocess.check_call():python2.5中新增的函数, 执行指定的命令, 如果执行成功则返回状态码, 否则抛出异常。1
subprocess.check_call(args, *, stdin=None, stdout=None, stderr=None, shell=False, timeout=None)举例如下:
1 | |
注意:
- args:表示shell指令,若以字符串形式给出shell指令,如"ls -l "则需要使shell = Ture。否则默认已数组形式表示shell变量,如"ls","-l"。
- 当使用比较复杂的shell语句时,可以先使用shlex模块的shlex.split()方法来帮助格式化命令,然后在传递给run()方法或Popen。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!