select、poll、epoll的原理
select、poll、epoll 的原理、比较、以及使用场景。
epoll 的水平触发与边缘触发(socket)。
参考连接
select,poll,epoll最简单的解释
知乎王伟豪
知乎裴浩
知乎明月照我心
简书六尺帐篷
select,poll详解
Select,Poll,Epoll 的差异与选择
高性能IO模型分析-浅析Select、Poll、Epoll机制(三)
select、poll、epoll的原理与区别
背景知识
用户空间和内核空间
操作系统根据寻址空间,划分为内核空间与用户空间。 对 32 位操作系统而言,它的寻址空间(虚拟地址空间,或叫线性地址空间)为 4G(2的32次方)。
Linux 操作系统将这4个G的寻址空间中高位1G字节为内核使用,就是内核空间;低位3G字节位用户使用 ,也就用户空间。
为啥要设置这两个空间?在 CPU 的所有指令中,有些指令是非常危险的,如果错用,将导致系统崩溃,比如清内存、设置时钟等。如果允许所有的程序都可以使用这些指令,那么系统崩溃的概率将大大增加。所以,CPU 将指令分为特权指令和非特权指令,对于那些危险的指令,只允许操作系统及其相关模块使用,普通应用程序只能使用那些不会造成灾难的指令。比如 Intel 的 CPU 将特权等级分为 4 个级别:Ring0~Ring3。其实 Linux 系统只使用了 Ring0 和 Ring3 两个运行级别(Windows 系统也是一样的)。当进程运行在 Ring3 级别(使用安全指令)时被称为运行在用户态,此时进程运行在用户空间。而运行在 Ring0 级别(使用危险指令)时被称为运行在内核态,此时程运行在内核空间中。
在内核态下,进程运行在内核地址空间中,此时 CPU 可以执行任何指令。运行的代码也不受任何的限制,可以自由地访问任何有效地址,也可以直接进行端口的访问。在用户态下,进程运行在用户地址空间中,被执行的代码要受到 CPU 的诸多检查,它们只能访问映射其地址空间的页表项中规定的在用户态下可访问页面的虚拟地址,且只能对任务状态段(TSS)中 I/O 许可位图(I/O Permission Bitmap)中规定的可访问端口进行直接访问。
区分内核空间和用户空间本质上是要提高操作系统的稳定性及可用性。
读写磁盘文件,分配回收内存,从网络接口读写数据等等都是在内核空间中完成的,应用程序是无法直接进行这样的操作的,但是我们可以通过内核提供的接口来完成这样的任务。对于从网络接口读写数据,我们就会用到socket。
socket
socket有三层含义:第一层是指一种通讯机制,第二层是指套接口,第二层是指套接字。
socket是一套用于Unix进程间通信的机制。 光有机制不行,还是要有代码实现这套机制才能做进一步开发,于是有人写代码实现了这套机制,这些代码就是这套通讯机制在操作系统(Unix、Mac O、Windows等)上的应用程序接口(套接口,,socket API),这就是上面所说的多个内核提供的接口中的一种,后面的程序员每次都调用这套API(套接口,套接字相关的接口,socket API)就能实现操作系统中进程之间的通信了(同一台机器上不同进程或者不同计算机上的进程间跨网络的通信都是通过套接口实现的)。最早实现这套API的是伯克利socket,后来Windows也实现了该接口。
现在,我们知道了socket的第一层和第二层含义了,那么第三层含义套接字(也是传播最广泛的含义),是什么意思?第三层含义就是:套接字就是使用套接口处理的文件描述符。
文件描述符 fd 和 套接字
文件描述符是Unix系统标识文件的int,Unix的哲学一切皆文件,所以各自资源(包括常规意义的文件、目录、管道、POSIX IPC)都可以看成文件。文件描述符是内核提供给用户来安全地操作文件的标识,不像指针,拥有了指针后你能随意修改文件。文件描述符在形式上是一个非负整数。实际上,它是一个索引值,该索引指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。
拥有了描述符后,你只能传入描述符给特定的接口,当你将文件描述符 fd 传入 套接口(socket API)时,这时候你就得到了传说中的套接字,进一步的进程之间的通讯以及数据的读写操作由内核读取用户输入的参数后来安全地执行。
也就是说,套接字就是使用套接口处理的文件描述符,因为是文件描述符,所以叫做套接"字"。而IP+端口就是网络socket(套接字)的地址,IP报文有8个字节分别代表源和目的地的IP地址,UDP头和TCP头有4个字节分别代表源和目的地的端口,就像以太头有12个字节分别代表源和目的地的MAC地址。
I/O操作
问:什么叫做I/O操作?
答:Linux系统继承了Unix系统的概念,一切皆文件。文件是指Linux系统中的VFS文件系统下的文件,VFS文件系统提供通用的接口对接各种类型的二进制流。因此,不管socket、还是FIFO、管道、终端等,对于LInux来说、一切都是文件、一切都是流。 在信息交换的过程中,对这些流进行数据的收发操作,就简称为I/O操作(input and output)。I/O分为磁盘I/O和网络I/O。访问的数据不在应用程序缓存中,那么每次数据都会直接从磁盘加载,或者应用程序需要哪从磁盘种读取书,就是磁盘I/O。而应用程序从网络中获取、分发数据说的就是网络I/O。
问:基于socket是什么类型的I/O? 答:socket是一种操作系统提供的进程间通信机制机,以及该机制在操作系统上的应用程序接口(socket API)。在TCP/IP协议中“IP地址 + TCP或UDP端口号”唯一标识网络通讯中的一个进程,“IP + 端口号”就称为套接字地址。在TCP协议中,建立连接的两个进程各自有一个socket来标识,那么两个socket组成的socket pair就唯一标识一个连接。应用程序可以通过套接字接口(socket API),来使用网络套接字,以进行数据交换。因此基于socket的I/O就是网络I/O。
问:网络I/O中会出现阻塞,请解释一下网络I/O阻塞出现的原因。
答:网络I/O阻塞产生的原因要从数据到达计算机设备开始理解:
1、数据从网线或者无线路由器以无线信号的方式到达计算机网卡,然后通过硬件电路的传输,最终会把数据写入到内存中的某个地址上。
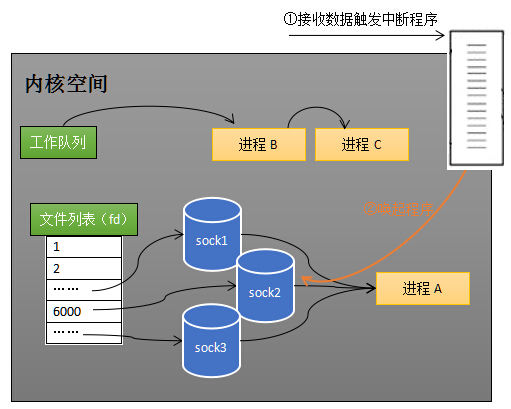
2、当网卡把数据写入到内存后,网卡向 CPU 发出一个中断信号,操作系统便能得知有新的网络数据到来,再通过网卡中断程序去处理数据。
3、当网卡发出的中断信号中断了CPU当前的进程,开启了网卡中断程序之后,就有可能产生阻塞。阻塞是指进程一直处于等待某事件(如接收到网络数据)发生之前的状态。不同情况下,计算机系统产生阻塞的原因不一样,和具体场景和任务流程有关,一个基础的网络程序如下:
1 | |
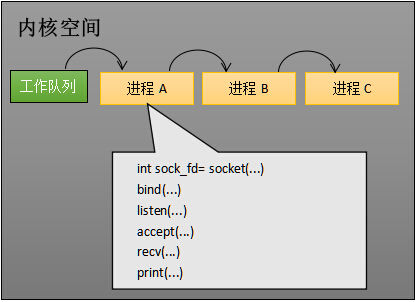
先新建 socket 对象,依次调用 bind、listen 与 accept,最后调用 receive 接收数据。其中recv 是个阻塞方法,当程序运行到 receive 时,它会一直等待来自内存的网络数据到达引发的中断信号,直到该中断信号到达,说明接收到数据才往下执行。这样一来就产生了一次I/O阻塞。阻塞的本质是什么 ?操作系统为了支持多任务,实现了进程调度的功能,会把进程分为“运行”和“等待”等几种状态。运行状态是进程获得 CPU 使用权,正在执行代码的状态;等待状态是阻塞状态,比如上述程序运行到 receive 时,程序会从运行状态变为等待状态,接收到数据后又变回运行状态。下图的计算机中运行着 A、B 与 C 三个进程(工作队列中有 A、B 和 C 三个进程),其中进程 A 执行着上述基础网络程序,一开始,这 3 个进程都被操作系统的工作队列所引用,处于运行状态,会分时执行。
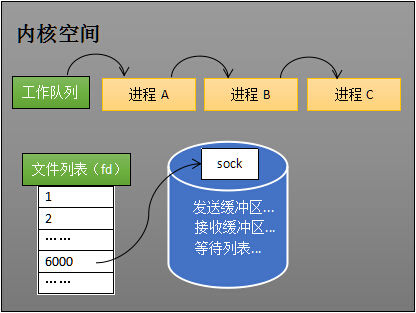
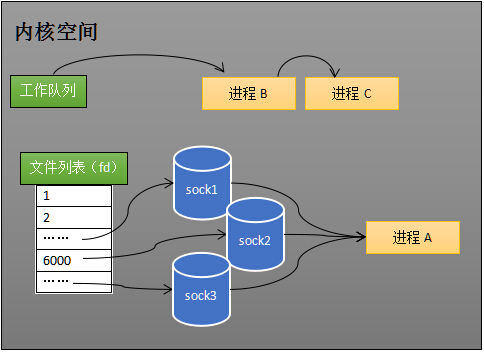
当进程 A 执行到创建 socket 的语句时,操作系统会创建一个由文件系统管理的 socket 对象(套接字对象,一个使用套接口处理的文件描述符,可以认为是一种特殊的数据结构 )(如下图)。这个 socket 对象(特殊的数据结构)包含了发送缓冲区、接收缓冲区与等待队列等成员三个组成部分。等待队列是个非常重要的结构,它指向所有需要等待该 socket 事件的进程。
当程序执行到 receive 时,操作系统会将进程 A 从工作队列移动到该 socket 的等待队列中(这个操作也就是把socket从运行空间拷贝到内核空间)(如下图)。由于工作队列只剩下了进程 B 和 C,依据进程调度,CPU 会轮流执行这两个进程的程序,不会执行进程 A 的程序。所以进程 A 被阻塞,不会往下执行代码,也不会占用 CPU 资源,但是会占用网络I/O,一直判断是否有进程A需要的网络数据达到。
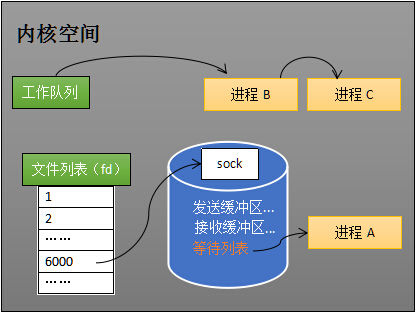
操作系统添加等待队列只是添加了对这个“等待中”进程的引用,以便在接收到数据时获取进程对象、将其唤醒,而非直接将进程管理纳入自己之下。上图为了方便说明,才直接将进程挂到等待队列之下。
当 socket 接收到数据后,操作系统将该 socket 等待队列上的进程重新放回到工作队列,该进程变成运行状态,继续执行代码。同时由于 socket 的接收缓冲区已经有了数据,receive 可以返回接收到的数据。
如下图所示,进程在 receive 阻塞期间,计算机收到了对端传送的数据(步骤①),数据经由网卡传送到内存(步骤②),然后网卡通过中断信号通知 CPU 有数据到达,CPU 执行中断程序(步骤③)。此处的中断程序主要有两项功能,先将网络数据写入到对应 socket 的接收缓冲区里面(步骤④),再唤醒进程 A(步骤⑤),重新将进程 A 放入工作队列中。
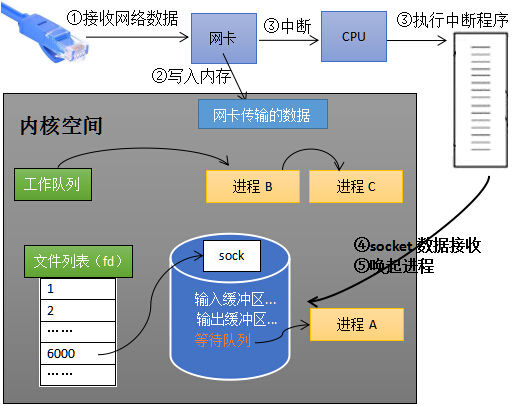
具体唤醒过程如下:
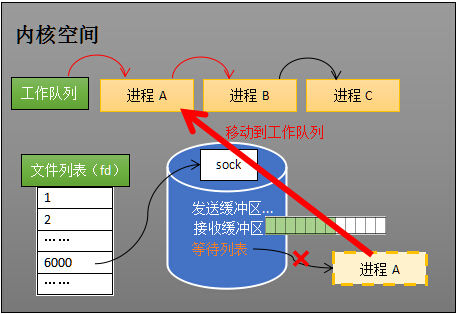
以上就是处于阻塞状态的进程在得知自己网络数据到来之后被唤起的过程(这种进程因为阻塞被挂起/放入等待队列,之后又被重新唤醒恢复执行的过程被称为进程切换),这里我们可能会思考一个问题,操作系统如何知道网络数据对应于哪个 socket?是这样的,因为一个 socket 对应着一个端口号,而网络数据包中包含了 ip 和端口的信息,内核可以通过端口号找到对应的 socket。当然,为了提高处理速度,操作系统会维护端口号到 socket 的索引结构,以快速读取。
I/O多路复用技术
问:很好,你已经说清楚了网路I/O阻塞的产生以及进程重新唤之后网路I/O阻塞消失的过程了,但是,如你所说,这种模式下,虽然不会占用 CPU 资源,但是会占用网络I/O,如何同时监视多个进程对应的 socket 数据是否到来,进而提高单个网络I/O的利用率呢?
答:上面的例子是典型的客户端/服务器(c/s demo)的通信模型,send/receive就是在一条I/O通道收发数据,这就是基本的网络I/O,但是这种操作不能充分利用所有网络I/O资源。而“I/O多路复用技术就可以解决这个问题,”I/O多路复用“实际上是指复用网络I/O从而使得多个I/O操作能在同一个网络I/O中执行。网络I/O使用socket套接字来通信,普通I/O模型只能监听一个socket,而I/O多路复用可同时监听多个socket,极大的提高了网络资源的利用率。
问:不错,说一下常见的几种I/O多路复用的机制吧。
答:
select机制
先理解不太高效的 select,假如能够预先传入一个 socket 列表(多个套接字),如果列表中的 socket 都没有数据,挂起进程,直到有一个 socket 收到数据,唤醒进程。这种方法很直接,也是 select 的设计思想。在下边的代码中,先准备一个数组 fds,让 fds 存放着所有需要监视的 socket。然后调用 select,如果 fds 中的所有 socket 都没有数据,select 会阻塞,直到有一个 socket 接收到数据,select 返回,唤醒进程。用户可以遍历 fds,通过 FD_ISSET 判断具体哪个 socket 收到数据,然后做出处理。
1 | |
select 的实现思路很直接,假如程序同时监视如下图的 sock1、sock2 和 sock3 三个 socket,那么在调用 select 之后,操作系统把进程 A 分别加入这三个 socket 的等待队列中(实际上就是把这三个套接字从运行空间拷贝到内核空间中,这里的拷贝涉及一次遍历)。
当任何一个 socket 收到数据后,中断程序将唤起进程。下图展示了 sock2 接收到了数据的处理流程,注: receive 和 select 的中断回调可以设置成不同的内容。
sock2 接收到了数据,中断程序唤起进程 A,所谓唤起进程,就是将进程从所有的等待队列中移除,加入到工作队列里面,如下图所示:
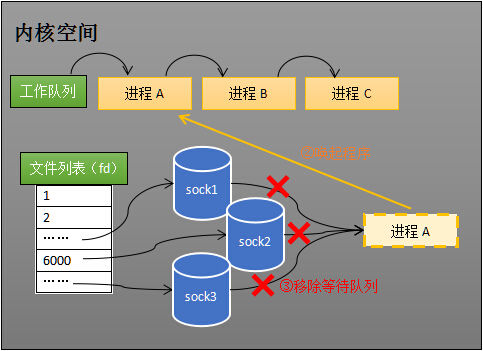
将进程 A 从所有等待队列中移除,再加入到工作队列里面,经由这些步骤,当进程 A 被唤醒后,它知道至少有一个 socket 接收了数据。程序只需遍历一遍 socket 列表,就可以得到就绪的 socket。
下面贴一下linux系统中 /usr/include/sys/select.h 文件中对 select 方法的定义:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26/* fd_set for select and pselect. */
typedef struct
{
/* XPG4.2 requires this member name. Otherwise avoid the name
from the global namespace. */
#ifdef __USE_XOPEN
__fd_mask fds_bits[__FD_SETSIZE / __NFDBITS];
# define __FDS_BITS(set) ((set)->fds_bits)
#else
__fd_mask __fds_bits[__FD_SETSIZE / __NFDBITS];
# define __FDS_BITS(set) ((set)->__fds_bits)
#endif
} fd_set;
/* Check the first NFDS descriptors each in READFDS (if not NULL) for read
readiness, in WRITEFDS (if not NULL) for write readiness, and in EXCEPTFDS
(if not NULL) for exceptional conditions. If TIMEOUT is not NULL, time out
after waiting the interval specified therein. Returns the number of ready
descriptors, or -1 for errors.
This function is a cancellation point and therefore not marked with
__THROW. */
extern int select (int __nfds, fd_set *__restrict __readfds,
fd_set *__restrict __writefds,
fd_set *__restrict __exceptfds,
struct timeval *__restrict __timeout);fd_set中最大的描述符+1,当调用select时,内核态会判断fd_set中描述符是否就绪,__nfds告诉内核最多判断到哪一个描述符。
__readfds、__writefds、__exceptfds都是结构体fd_set,fd_set可以看作是一个描述符的集合。 select函数中存在三个fd_set集合,分别代表三种事件,readfds表示读描述符集合,writefds表示读描述符集合,exceptfds表示异常描述符集合。当对应的fd_set = NULL时,表示不监听该类描述符。
timeval __timeout用来指定select的工作方式,即当文件描述符尚未就绪时,select是永远等下去,而是等待一定的时间,即使没有socket就绪,也直接返回。
函数返回值int表示: 就绪描述符的数量,如果为-1表示产生错误 。
fd 就是 文件描述符 file descriptor**
运行机制:Select会将全量fd_set从用户空间拷贝到内核空间,并注册回调函数, 在内核态空间来判断每个请求是否准备好数据 。select在没有查询到有文件描述符(就是套接字)就绪的情况下,将一直阻塞(就是一直等在 receive 那里)。如果有一个或者多个描述符(就是套接字)就绪,那么select将就绪的文件描述符(就是套接字)置位,然后select返回。返回后,由程序遍历查看哪个请求有数据。
优点
这种简单方式行之有效,在几乎所有操作系统都有对应的实现。
缺点
- 每次调用 select 都需要将进程加入到所有 socket 的等待队列(套接字集合拷贝),每次唤醒都需要从每个队列中移除(检查到底是哪一个套接字就绪了),这里涉及了两次遍历。
- 第一次遍历:每次都要将整个 fds 列表(就是套接字集合)传递给内核,这个传递,说白了就是将整个 fds 列表(就是套接字集合)从用户态拷贝到内核态,这波操作有一定的开销,而且fd越多开销则越大。
- 第二次遍历:进程被唤醒后,程序并不知道哪些 socket 收到数据,select返回的是整个socket 数组的句柄。应用程序需要遍历整个socket 数组才知道谁发生了变化(谁就绪了),轮询代价大。
- 每次都会拷贝,每次都要轮询,最大开销和fds列表(就是套接字集合)中的fd(文件描述符/套接字)有关,为了防止fds太大,拷贝、轮询的开销太大,所以fds的长度是有限制的。Select的
fd_set是基于一个位掩码(bit mask)实现的,因此fd_set有固定的长度,一般是32*32=1024,数组元素的每一位对应一个文件描述符。例如,一个int整数占32位,那么32个int整数组成的数组,第一个元素代表文件描述符0到31,数组的第二个元素代表文件描述符32到63,以此类推,fd_set可以表示1024个文件描述符的就绪情况,所以默认就只能监视 1024 个socket。内核在被编译的时候,可以不受这个长度的限制,因为select()允许应用程序自定义FD_SETSIZE的大小(在如今的系统头文件中可以看到这一点),但是这会增加额外的支出。
注意:这里只解释了 select 的一种情形。当程序调用 select 时,内核会先遍历一遍 socket,如果有一个以上的 socket 接收缓冲区有数据,那么 select 直接返回,不会阻塞。这也是为什么 select 的返回值有可能大于 1 的原因之一。如果没有 socket 有数据,说明该进程需要的网络数据还没到达,进程才会阻塞,才会处于等待状态。
使用场景
- 可移植性好,几乎适用于所有平台。select已经存在很长时间了,你可以确定每个支持网络和非阻塞套接字的平台都会支持select,而它可能还不支持poll。另一种选择是你仍然使用poll然后在那些没有poll的平台上使用select来模拟它。
- select的超时时间理论上可以精确到纳秒级别。而poll和epoll的精度只有毫秒级。这对于桌面或者服务器系统来说没有任何区别,因为它们不会运行在纳秒精度的时钟上,但是在某些与硬件交互的实时嵌入式平台,降低控制棒关闭核反应堆.可能是需要的。(这就可以作为一个更加精确的sleep()来用)
- select的缺点,使得其无法支持高并发连接。假设我们的服务器需要支持100万的并发连接,则在_FD_SETSIZE为1024的情况下,则我们至少需要开辟1k个进程才能实现100万的并发连接。除了进程间上下文切换的时间消耗外,从内核/用户空间大量的无脑内存拷贝、数组轮询等,是系统难以承受的。因此,基于select模型的服务器程序,要达到10万级别的并发访问,是一个很难完成的任务。
触发方式
select的触发方式是水平触发,应用程序如果没有完成对一个已经就绪的文件描述符进行IO,那么之后再次select调用还是会将这些文件描述符通知进程。
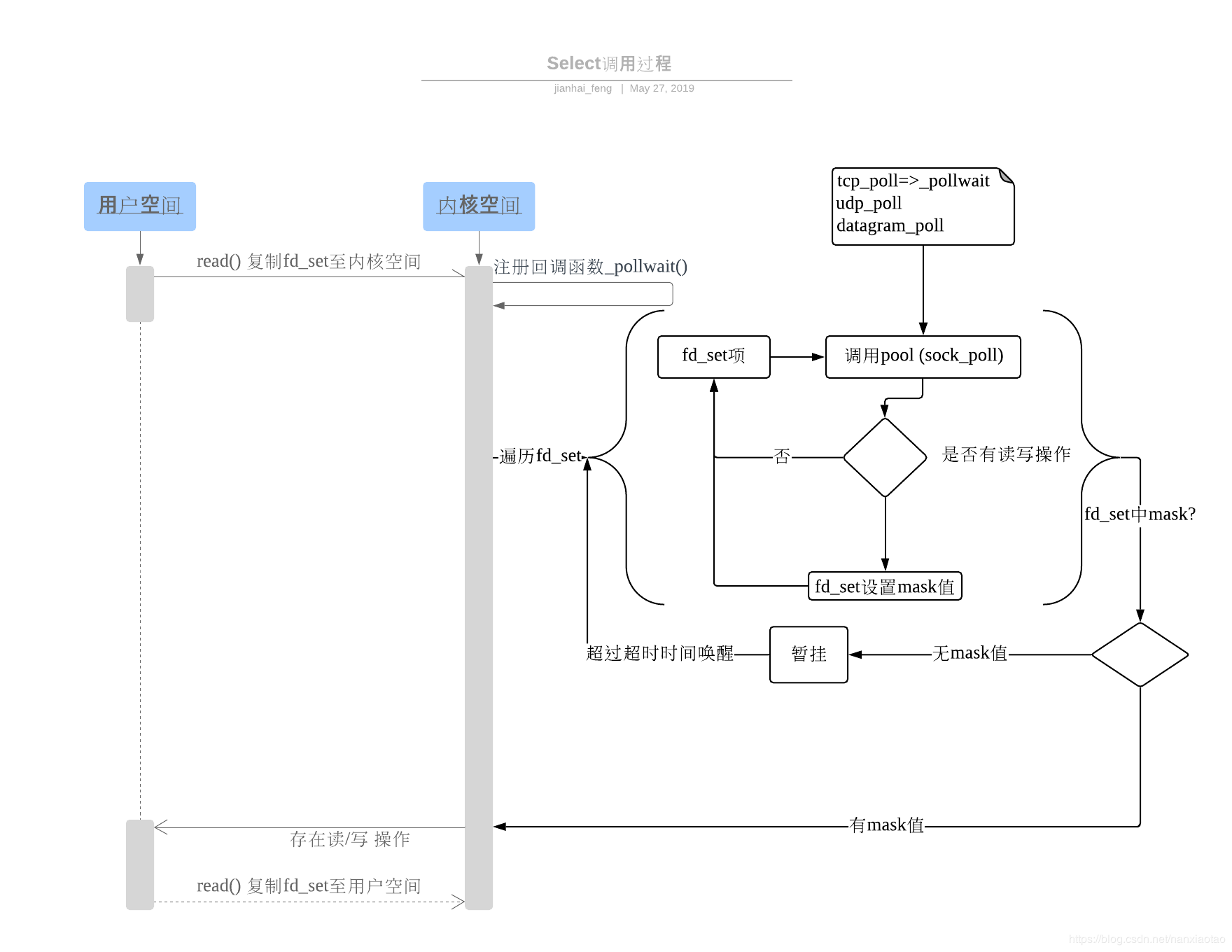
select完整调用过程,参看下图:
poll机制
linux系统中/usr/include/sys/poll.h文件中对poll方法的定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17/* Data structure describing a polling request. */
struct pollfd
{
int fd; /* File descriptor to poll. */
short int events; /* Types of events poller cares about. */
short int revents; /* Types of events that actually occurred. */
};
/* Poll the file descriptors described by the NFDS structures starting at
FDS. If TIMEOUT is nonzero and not -1, allow TIMEOUT milliseconds for
an event to occur; if TIMEOUT is -1, block until an event occurs.
Returns the number of file descriptors with events, zero if timed out,
or -1 for errors.
This function is a cancellation point and therefore not marked with
__THROW. */
extern int poll (struct pollfd *__fds, nfds_t __nfds, int __timeout);pollfd,用来指定一个需要监听的描述符。结构体中fd为需要监听的文件描述符,events为需要监听的事件类型,而revents为经过poll调用之后返回的事件类型,在调用poll的时候,一般会传入一个pollfd的结构体数组,数组的元素个数表示监控的描述符个数。
__nfds和__timeout**参数都和Select机制中的同名参数含义类似。
下面是一个典型的程序流程:基本与select相同:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29// The structure for two events
struct pollfd fds[2];
// Monitor sock1 for input
fds[0].fd = sock1;
fds[0].events = POLLIN;
// Monitor sock2 for output
fds[1].fd = sock2;
fds[1].events = POLLOUT;
// Wait 10 seconds
int ret = poll( &fds, 2, 10000 );
// Check if poll actually succeed
if ( ret == -1 )
// report error and abort
else if ( ret == 0 )
// timeout; no event detected
else
{
// 如果我们检测到事件,请将其归零,以便我们可以重用该结构
if ( pfd[0].revents & POLLIN )
pfd[0].revents = 0;
// input event on sock1
if ( pfd[1].revents & POLLOUT )
pfd[1].revents = 0;
// output event on sock2
}
- Poll描述fd集合(也就是套接字集合)的方式select不同,poll使用
pollfd结构(也就是链表结构)而不是select的fd_set结构(也就是bit mask结构),所以poll是没有最大连接数的限制,可以超过1024。
- 它不会修改struct pollfd数据中传递的数据。因此,只要将生成事件的描述符的revents成员设置为零,就可以在poll()调用之间重用它。
- 相比于select来说可以更好的控制事件。例如,它可以检测对端套接字是否关闭而不需要监听它的读事件。
Poll缺点
- Poll和selec本质上都差不多,就是改了fds的集合的数据结构,突破了1024的限制。但还是必须通过遍历描述符列表(套接字集合 fds)来查找哪些描述符(套接字)接收到了数据或者发出了数据。更糟糕的是在内核空间也需要通过遍历来找到哪些套接字正在被监听,然后再重新遍历整个列表来设置事件。(简而言之,和select一样,要来回拷贝,要遍历整个套接字集合寻找就绪的套接字。)
运行机制
- poll的实现和select非常相似,只是描述fd集合的方式不同,同时,poll相对于select最大的特点就是将需要监听的事件和返回的事件封装到一个结构体当中,不需要像select那样每次都要重新进行设置,并且poll并没有最大值的限制。poll使用pollfd结构代替select的fd_set(网上讲:类似于位图)结构,所以Poll机制突破了Select机制中的文件描述符数量最大为1024的限制。
使用场景
- 跨平台
- 同一时刻你的应用程序监听的套接字少于1000(这种情况下使用epoll不会得到任何益处)。
- 同一时刻一次监视超过1000个套接字,但连接非常短暂。
触发方式
poll有一个特点是水平触发,也就是通知进程fd就绪(套接字就绪)后,这次没有被处理,那么下次poll的时候会再次通知同个fd已经就绪。
epoll机制
epoll相对于select、poll的改进
之所以是e-poll,是因为它是event事件驱动
epoll 通过以下一些措施来改进效率:
措施一:功能分离
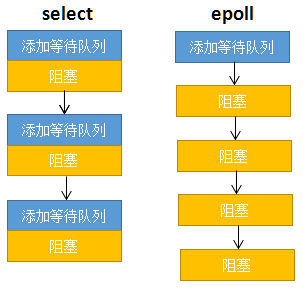
select 低效的原因之一是将“维护等待队列”和“阻塞进程”两个步骤合二为一。如下图所示,每次调用 select 都需要这两步操作,然而大多数应用场景中,需要监视的 socket 相对固定(一般进程绑定的端口不会改变,QQ一般是4000),并不需要每次都修改。epoll 将这两个操作分开,先用 epoll_ctl 维护等待队列,再调用 epoll_wait 阻塞进程。显而易见地,效率就能得到提升。
相比 select,epoll 拆分了功能,为方便理解后续的内容,我们先了解一下 epoll 的用法。如下的代码中,先用 epoll_create 创建一个 epoll 对象 epfd,再通过 epoll_ctl 将需要监视的 socket 添加到 epfd 中,最后调用 epoll_wait 等待数据:
1
2
3
4
5
6
7
8
9
10
11
12
13int s = socket(AF_INET, SOCK_STREAM, 0);
bind(s, ...)
listen(s, ...)
int epfd = epoll_create(...);
epoll_ctl(epfd, ...); //将所有需要监听的socket添加到epfd中
while(1){
int n = epoll_wait(...)
for(接收到数据的socket){
//处理
}
}
措施二:就绪列表
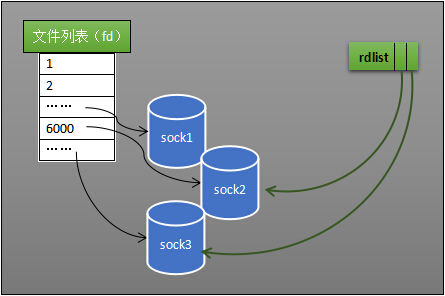
select 低效的另一个原因在于程序不知道哪些 socket 收到数据,只能一个个遍历。如果内核维护一个“就绪列表”,引用收到数据的 socket,就能避免遍历。如下图所示,计算机共有三个 socket,收到数据的 sock2 和 sock3 被就绪列表 rdlist 所引用。当进程被唤醒后,只要获取 rdlist 的内容,就能够知道哪些 socket 收到数据。
epoll 的原理与工作流程
(1)、创建 epoll 对象
如下图所示,当某个进程调用 epoll_create 方法时,内核会创建一个 eventpoll 对象(也就是上面程序中 epfd 所代表的对象)。eventpoll 对象也是文件系统中的一员,和 socket 一样,它也会有等待队列。
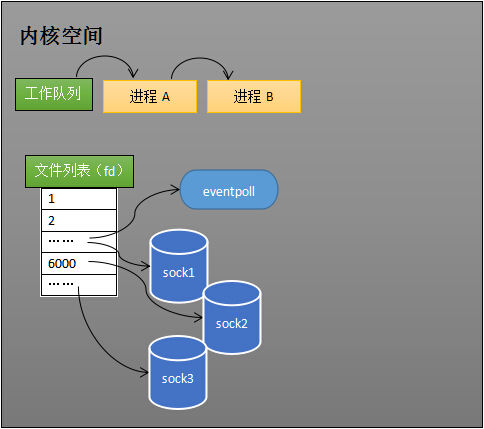
创建一个代表该 epoll 的 eventpoll 对象是必须的,因为内核要维护“就绪列表”等数据,“就绪列表”会作为 eventpoll 的成员。
(2)、维护监视列表
创建 epoll 对象后,可以用 epoll_ctl 添加或删除所要监听的 socket。以添加 socket 为例,如下图,如果通过 epoll_ctl 添加 sock1、sock2 和 sock3 的监视,内核会将 eventpoll 添加到这三个 socket 的等待队列中。
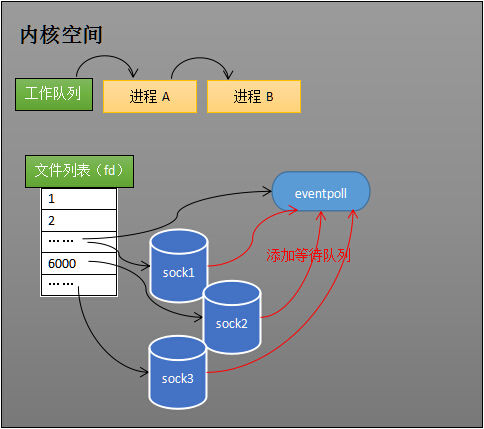
当 socket 收到数据后,中断程序会操作 eventpoll 对象,而不是直接操作进程。
(3)、接收数据
当 socket 收到数据后,中断程序会给 eventpoll 的“就绪列表”添加 socket 引用。如下图展示的是 sock2 和 sock3 收到数据后,中断程序让 rdlist 引用这两个 socket。
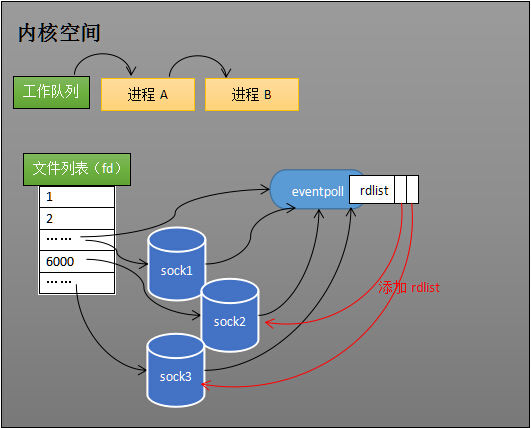
eventpoll 对象相当于 socket 和进程之间的中介,socket 的数据接收并不直接影响进程,而是通过改变 eventpoll 的就绪列表来改变进程状态。当程序执行到 epoll_wait 时,如果 rdlist 已经引用了 socket,那么 epoll_wait 直接返回,如果 rdlist 为空,阻塞进程。
(4)、阻塞和唤醒进程
假设计算机中正在运行进程 A 和进程 B,在某时刻进程 A 运行到了 epoll_wait 语句。如下图所示,内核会将进程 A 放入 eventpoll 的等待队列中,阻塞进程。
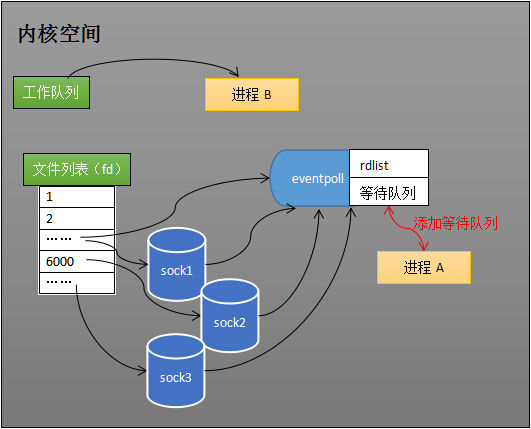
当 socket 接收到数据,中断程序一方面修改 rdlist,另一方面唤醒 eventpoll 等待队列中的进程,进程 A 再次进入运行状态(如下图)。也因为 rdlist 的存在,进程 A 可以知道哪些 socket 发生了变化。
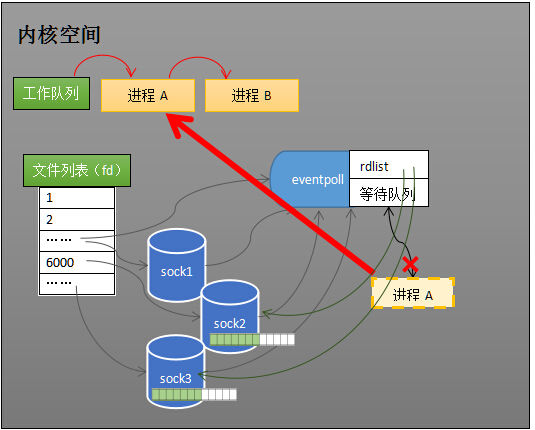
简而言之就是四步骤
第一步、创建 epoll 对象 eventpoll
第二步、向 eventpoll 的监听队列中添加socket(套接字)
第三步、假设进程A运行到 epoll_wait 语句,将推出工作队列,进入 eventpoll 的等待队列。 第四步、接收到网络数据,引发中断之后,中断程序(在内核空间中)会向 eventpoll 的 “就绪列表”(rdlist) 中添加接收到网络数据的 socket 的引用。并唤醒进程A,进程A在epoll机制下,就不用像之前select、poll机制那样遍历所有socket了,通过rdlist就可以知道是哪一个socket里面有新接收的网络数据。
eventpoll 的数据结构
如下图所示,eventpoll 包含了 lock、mtx、wq(等待队列)与 rdlist 等成员,其中 rdlist (负责保存已经就绪的socket)和 rbr(负责保存所有待监听的socket)是我们所关心的。
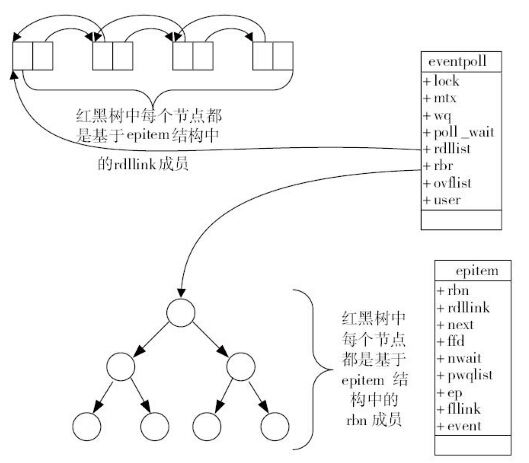
就绪列表引用着就绪的 socket,所以它应能够快速的插入数据。程序可能随时调用 epoll_ctl 添加监视 socket,也可能随时删除。当删除时,若该 socket 已经存放在就绪列表中,它也应该被移除。所以就绪列表应是一种能够快速插入和删除的数据结构。双向链表就是这样一种数据结构,epoll 使用双向链表来实现就绪队列(对应上图的 rdllist)。
既然 epoll 将“维护监视队列”和“进程阻塞”分离,也意味着需要有个数据结构来保存监视的 socket,至少要方便地添加和移除,还要便于搜索,以避免重复添加。红黑树是一种自平衡二叉查找树,搜索、插入和删除时间复杂度都是O(log(N)),效率较好,epoll 使用了红黑树作为索引结构(对应上图的 rbr)。
linux系统中/usr/include/sys/epoll.h文件中有如下方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27/* Creates an epoll instance. Returns an fd for the new instance.
The "size" parameter is a hint specifying the number of file
descriptors to be associated with the new instance. The fd
returned by epoll_create() should be closed with close(). */
extern int epoll_create (int __size) __THROW;
/* Manipulate an epoll instance "epfd". Returns 0 in case of success,
-1 in case of error ( the "errno" variable will contain the
specific error code ) The "op" parameter is one of the EPOLL_CTL_*
constants defined above. The "fd" parameter is the target of the
operation. The "event" parameter describes which events the caller
is interested in and any associated user data. */
extern int epoll_ctl (int __epfd, int __op, int __fd,
struct epoll_event *__event) __THROW;
/* Wait for events on an epoll instance "epfd". Returns the number of
triggered events returned in "events" buffer. Or -1 in case of
error with the "errno" variable set to the specific error code. The
"events" parameter is a buffer that will contain triggered
events. The "maxevents" is the maximum number of events to be
returned ( usually size of "events" ). The "timeout" parameter
specifies the maximum wait time in milliseconds (-1 == infinite).
This function is a cancellation point and therefore not marked with
__THROW. */
extern int epoll_wait (int __epfd, struct epoll_event *__events,
int __maxevents, int __timeout);
epoll_ctl函数:向epoll中注册事件,该函数如果调用成功返回0,否则返回-1。
- __epfd为epoll_create返回的epoll实例 - __op表示要进行的操作 - __fd为要进行监控的文件描述符 - __event要监控的事件
epoll_wait函数:类似与select机制中的select函数、poll机制中的poll函数,等待内核返回监听描述符的事件产生。该函数返回已经就绪的事件的数量,如果为-1表示出错。 当调用epoll_wait检查是否有事件发生时,只需要检查eventpoll对象中的rdlist双链表中是否有epitem元素即可。如果rdlist不为空,则把发生的事件复制到用户态,同时将事件数量返回给用户。
- __epfd为epoll_create返回的epoll实例
- __events数组为 epoll_wait要返回的已经产生的事件集合
- __maxevents为希望返回的最大的事件数量(通常为__events的大小)
- __timeout和select、poll机制中的同名参数含义相同
运行机制
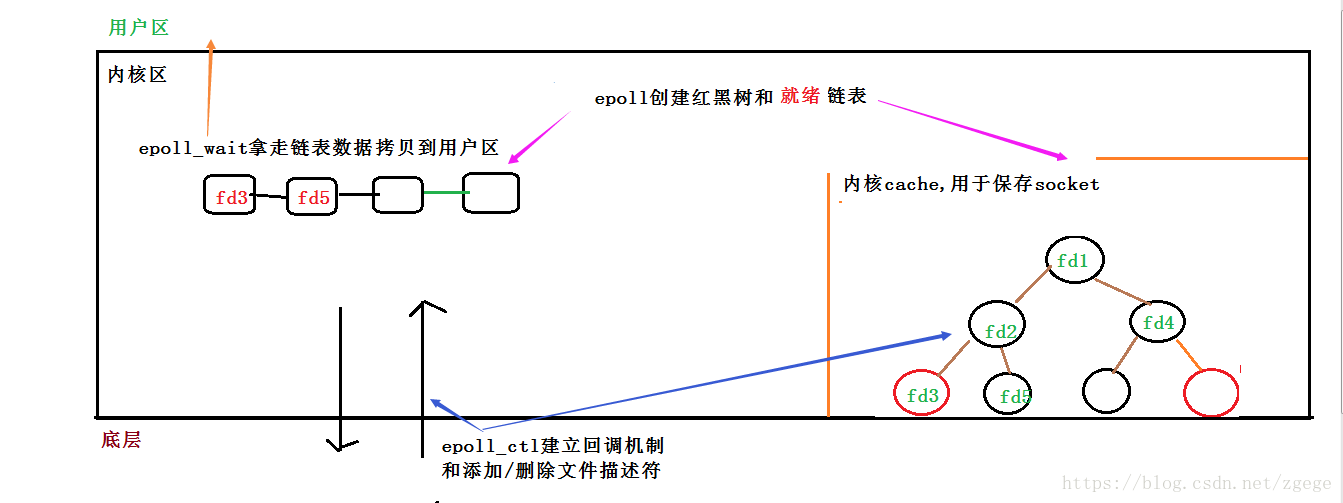
epoll操作过程需要上述三个函数,也正是通过三个函数完成Select机制中一个函数完成的事情,解决了Select机制的三大缺陷(内核空间拷贝、遍历选择就绪socket、1024长度限制)。
- 对于第一个缺点,epoll的解决方案是:通过
eventpoll对象在用户态和内核态之间之间共享fds(套-接字集合),所以可以不必进行从用户态到内核态的一个拷贝,大大节约系统资源。
- 对于第二个缺点,epoll的解决方案不像select或poll一样每次都把当前进程轮流加入fd(套接字)对应的设备等待队列中,而只在
epoll_ctl时把当前进程挂一遍(这一遍必不可少),并为每个fd(套接字)指定一个回调函数。当套接字就绪时,唤醒等待队列上的等待者时,就会调用这个回调函数,而这个回调函数会把就绪的fd(套接字)加入一个就绪链表。那么当我们调用epoll_wait时,epoll_wait只需要检查链表中是否有存在就绪的fd(套接字)即可,效率非常可观。
- 对于第三个缺点,fd(套接字)数量的限制,也只有Select存在,Poll和Epoll都不存在。由于Epoll机制中只关心就绪的fd(套接字),它相较于Poll需要关心所有fd,在连接较多的场景下,效率更高。在1GB内存的机器上大约是10万左右,一般来说这个数目和系统内存关系很大。
优点
- 使用内存映射技术(也就是声明
eventpoll对象),节省了用户态和内核态间数据拷贝的资源消耗。
- 通过每个fd定义的回调函数来实现的,只有就绪的fd才会执行回调函数。I/O的效率不会随着监视fd的数量的增长而下降。
- 文件描述符数量不再受限。
缺点
- 改变监听事件的类型(例如从读事件改为写事件)需要调用
epoll_ctl系统调用,先删除后添加,而这在poll中只需要在用户空间简单的设置一下对应的掩码。如果需要改变5000个套接字的监听事件类型就需要5000次系统调用和上下文切换(直到2014年epoll_ctl函数仍然不能批量操作,每个描述符只能单独操作),这在poll中只需要循环一次pollfd结构体。
- 每一个被
accept()的套接字都需要添加到集合中,在epoll中必须使用epoll_ctl来添加–这就意味着每一个新的连接都需要两次系统调用,而在poll中只需要一次。如果你的服务有非常多的短连接它们都接受或者发送少量数据,epoll所花费的时间可能比poll更长。(解释了上文) - epoll是Linux上独有的,虽然其他平台上也有类似的机制但是他们的区别非常大,例如边沿触发这种模式是非常独特的(FreeBSD的kqueue对它的支持非常粗糙)。
触发方式
- 水平触发(LT):若就绪的事件一次没有处理完要做的所有事件,就会一直去处理。将没有处理完的事件继续放回到就绪队列之中(即那个内核中的链表),一直进行处理。 具体代码实现上是将没处理完的放在 rdlist 的最前面,然后跟着下次需要返回的一起返回。
- 边缘触发(ET):就绪的事件只能处理一次,若没有处理完会在下次的其它事件就绪时再进行处理。而若以后再也没有就绪的事件,那么剩余的那部分数据也会随之而丢失,具体实现就是从 rdlist 上删除了。
由此可见:ET模式的效率比LT模式的效率要高很多。只是如果使用ET模式,就要保证每次进行数据处理时,要将其处理完,不能造成数据丢失,这样对编写代码的人要求就比较高。 注意:ET模式只支持非阻塞的读写:为了保证数据的完整性。
应用场景
- 你的程序通过多个线程来处理大量的网络连接。如果你的程序只是单线程的那么将会失去epoll的很多优点。并且很有可能不会比poll更好。
- 你需要监听的套接字数量非常大(至少1000)。如果监听的套接字数量很少则使用epoll不会有任何性能上的优势甚至可能还不如poll。
- 你的网络连接相对来说都是长连接。就像上面提到的epoll处理短连接的性能还不如poll因为epoll需要额外的系统调用来添加描述符到集合中。
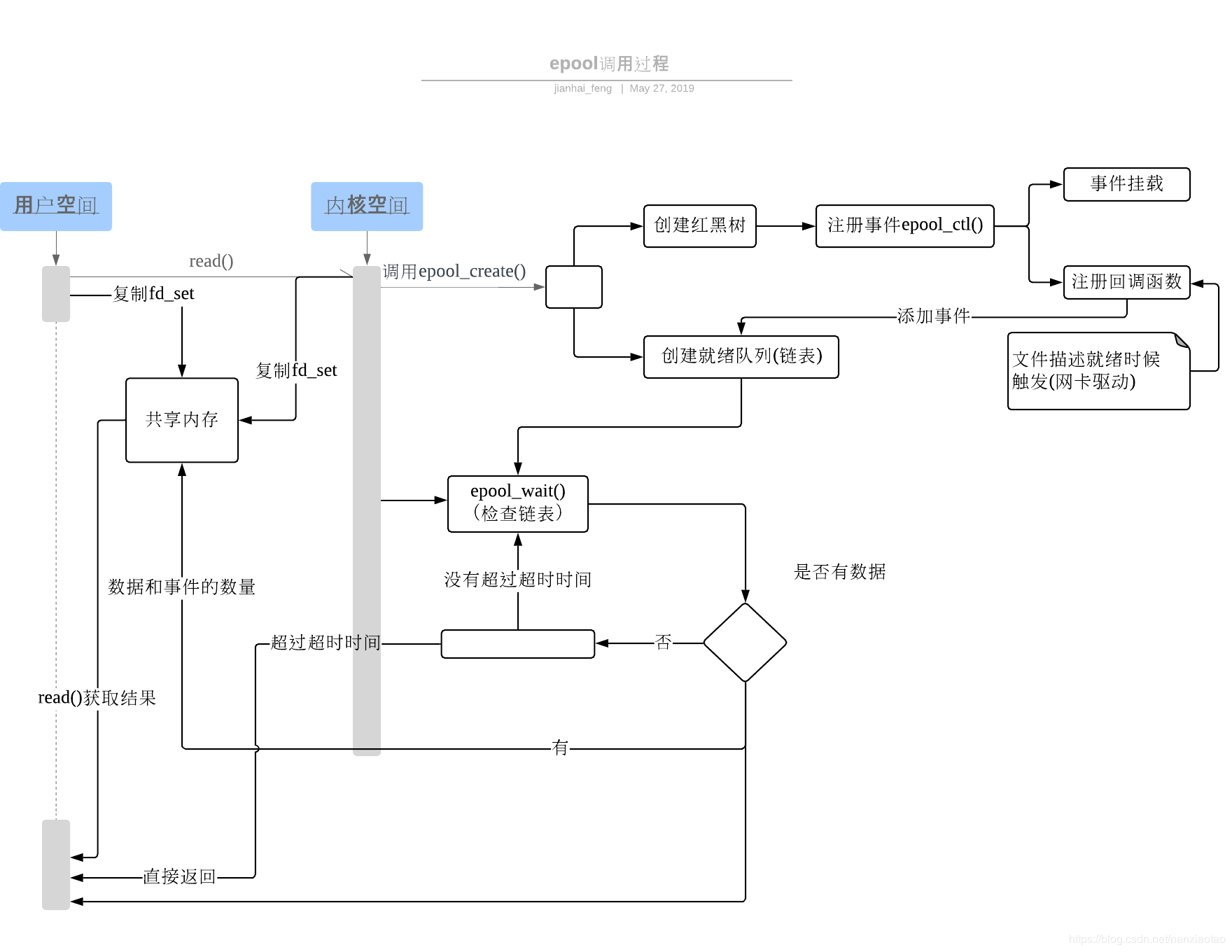
epoll完整调用过程,参看下图:
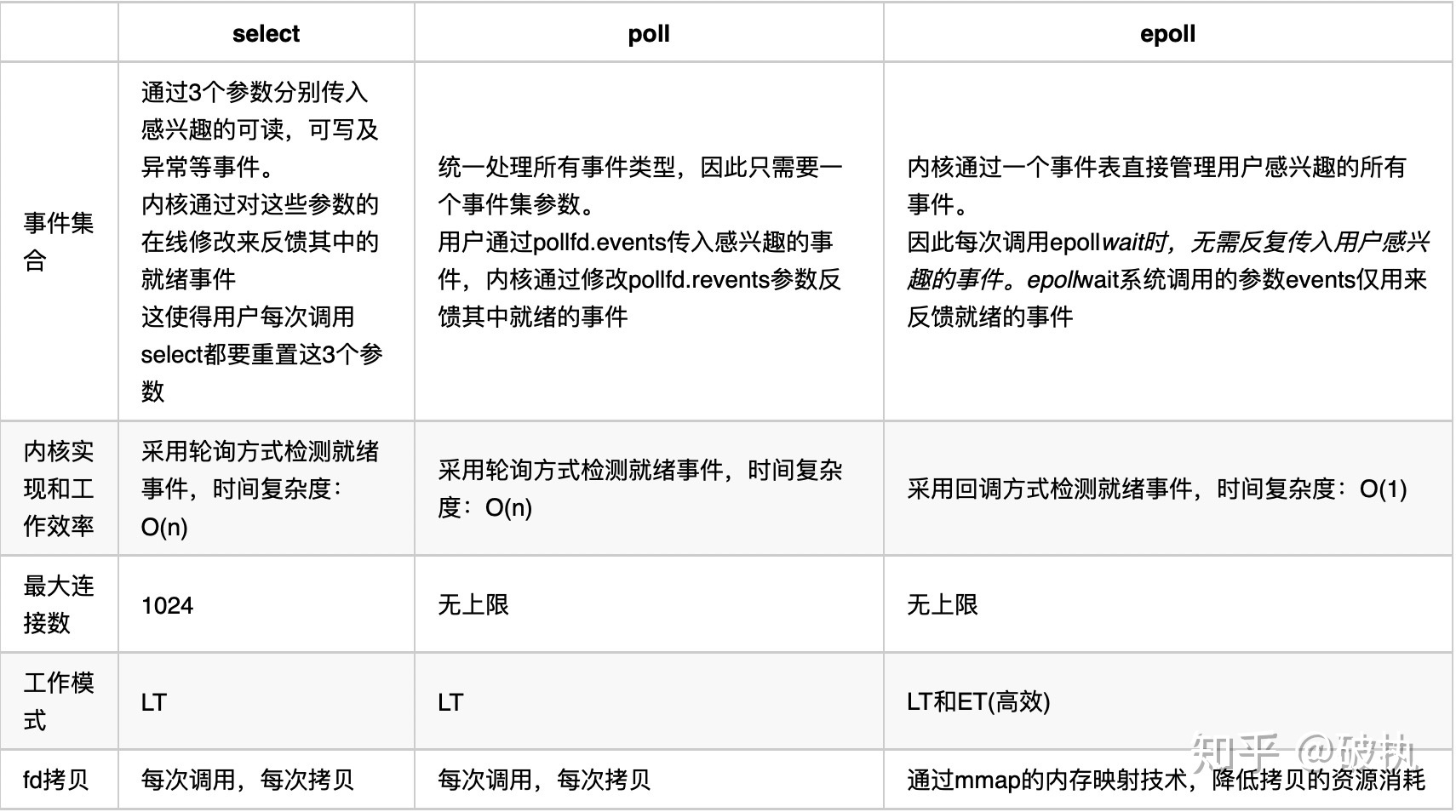
几种机制的对比,如下图所示:
问:很好,你说已经清楚了select、poll、epoll 的原理、比较、以及使用场景,epoll 的水平触发与边缘触发等问题,面试结果将在几天之后通知你。 答:好的,谢谢。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!