从GMM-HMM到端对端
语言识别的历史长河:从GMM-HMM到端对端
基本概念
ASR定义
从语音信号到文本记录 From Speech Signal to Transcript

ASR(Automatic Speech Recognition)定义:给定一个语音信号,找到最有可能与之对应的词序列的过程就是自动语音识别。 \[ \hat{W} = argmax\ p(W|X) \] \(X\) 是输入的语音信号,\(W\) 就是我们最终要求解的词序列,找最有可能得过程就是计算条件概率 \(p(W|X)\)的过程。对该条件概率进行贝叶斯拆解,可以得到 : \[ \hat{W} = argmax\ \frac{p(W)p(X|W)}{p(X)} \] 对于任何一个 \(p(W)\) (语言模型,描述的是词序列本身发生的概率),\(p(X)\)(语音信号本身发生的概率)和 \(p(W)\) 没有关系,是一个独立概率,所以上式可以简化为: \[ \hat{W} = argmax\ p(W)p(X|W) \]
连在一起就是: \[ \hat{W} = argmax\ p(W|X) = argmax \frac{p(W)p(X|W)}{p(X)} = argmax\ p(W)p(X|W) \]
由此可知,一个语音识别问题的解决,可以分为三个部分:
Decoder: \(argmax()\) 一个搜索、求解、找到使得条件概率 \(p(W|X)\)最大的 \(W\) 的方法。 Acoustic Model:\(p(X|W)\),声学模型,描述词序列和语音信号之间的关系。 Language Model:\(p(W)\),语言模型,描述的是词序列本身发生的概率。
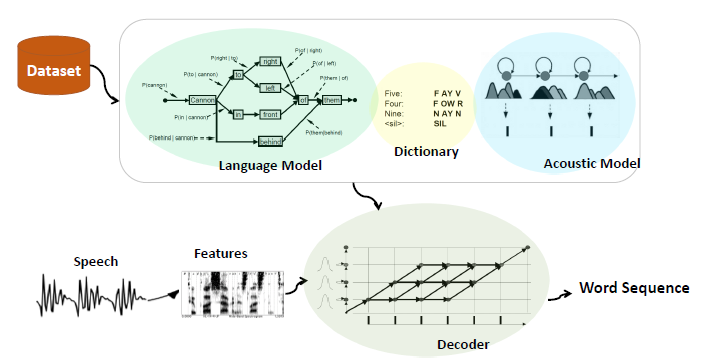
框架 FrameWork
语言模型和声学模型,是基于一些语音语料库得到的。发音词典(Dictionary)则是语言模型和声学模型之间的桥梁,当声学模型和语言模型采取不同的建模单元的时候。比如语言模型以词作为基本的建模单元,而声学模型以声母、韵母作为基本的建模单元,这时候就可以利用发音词典来完成一个映射。
分类说明
语言模型 Language Model
基于马尔可夫假设的N元文法语言模型 N-gram language model based on the Markov hypothesis
马尔科夫假设:随意一个词出现的概率只与它前面出现的有限的一个或者几个词有关。换而言之,当计算有很长词历史的句子的发生概率时,只考虑当前词之前的N个词作为词历史(词历史也就是条件)来代替很长的词历史。
如果一个词的出现与它周围的词是独立的,那么我们就称之为unigram,也就是一元语言模型: \[ p(S) = p(w_1, w_2, w_3, ..., w_{m-1}, w_{m}) \]
\[ p(S) \approx p(w_1)p(w_2)p(w_3)...p(w_n) \]
如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为bigram,也就是二元语言模型: \[ p(S) = p(w_1, w_2, w_3, ..., w_{m-1}, w_{m}) \]
\[ p(S) \approx p(w_1)p(w_2|w_1)p(w_3|w_2)...p(w_n|w_{n-1}) \]
假设一个词的出现仅依赖于它前面出现的两个词,那么我们就称之为trigram,也就是三元语言模型: \[ p(S) = p(w_1, w_2, w_3, ..., w_{m-1}, w_{m}) \]
\[ p(S) \approx p(w_1)p(w_2|w_1)p(w_3|w_2, w_1)...p(w_n|w_{n-1}, w_{n-2}) \]
N元模型就是假设当前词的出现概率只与它前面的N-1个词有关。而这些概率参数都是可以通过大规模语料库来计算,比如三元概率有: \[ p(w_i|w_{i-1}, w_{i-2}) \approx \frac{count(w_{i-2}w_{i-1}w_{i})}{count(w_{i-2}w_{i-1})} \]
在实践中用的最多的就是bigram和trigram了,高于四元的用的非常少,由于训练它须要更庞大的语料,并且数据稀疏严重,时间复杂度高,精度却提高的不多。
优点:1、查表操作即可获得N元文法的得分,计算速度快,开销小。如果用神经网络,需要矩阵乘法才行。2、N-gram的效果随着在语料库规模的增大而增大。
实际应用:当我们遇到一个新的语音识别问题的时候,新收集尽可能多的语料组织语料库(上T级别)来训练一个语言模型,可以有效的提升效果。
建模单元:以汉语为例,可以用字做建模单元、也可以用词做建模单元,不同长度的词会影响最终语言模型的效果,一般来说,基于词的语言模型由于融合了一些结构信息,所以效果会更好。在收集得到的语料库上,按照建模单元(字、词)进行分词。
N-gram公式推导 \[ p(S) = p(w_1, w_2, w_3, ..., w_{m-1}, w_{m}) \]
等价于,这里的约等于 \(\approx\) 就体现了马尔可夫假设。 \[ p(S) = p(w_1)p(w_2|w_1)p(w_3|w_1, w_2)p(p_4| w_1, w_2, w_3)...p(w_m|w_1, w_2, w_3, ..., w_{m-1}) \]
\[ p(S) = \prod_{i=1}^m\ p(w_i|w_1, w_2, w_3, ..., w_{i-1}) \]
\[ p(S) \approx \prod_{i=1}^m\ p(w_i|w_{i-(n-1)}, w_{i-(n-2)}, ..., w_{i-1}) \]
解码器 Decoder
解码器做的一个重要的事情就是搜索,就是把语言模型和声学模型整合起来去搜索得到一条最优的路径。
当我们基于语言模型和声学模型构建好发音字典之后,我们可以通过发音字典去构建一个搜索解码网络。基于这个网络中搜索得到的路径,我们可以得到一个N元文法的得分。同时我们也可以把解码过程中得到的声学模型的得分和N元文法的得分融合起来。
这样就需要两个部分:搜索算法、解码网络
- 搜索算法
Viterbi Algorithm(一个DP动态规划的算法)
- 解码网络
分为动态解码网络和静态解码网络两种
基于发音词典获得解码网络,然后动态的融合语言模型,这种解,网络属于动态解码网络,特点是语言模型信息是查找之后放进去的,而非一开始就在搜索网络里面。
而静态解码网络是把语言模型的信息在一开始就融合进了搜索解码网络中。常用WFST/Weighted Finite State Transducers,一种形式化的表示语言,能够将发音词典和语言模型以同种方式表示并融合到同一个网络中。
声学模型 Acoustic Model
声学模型中的多样性问题
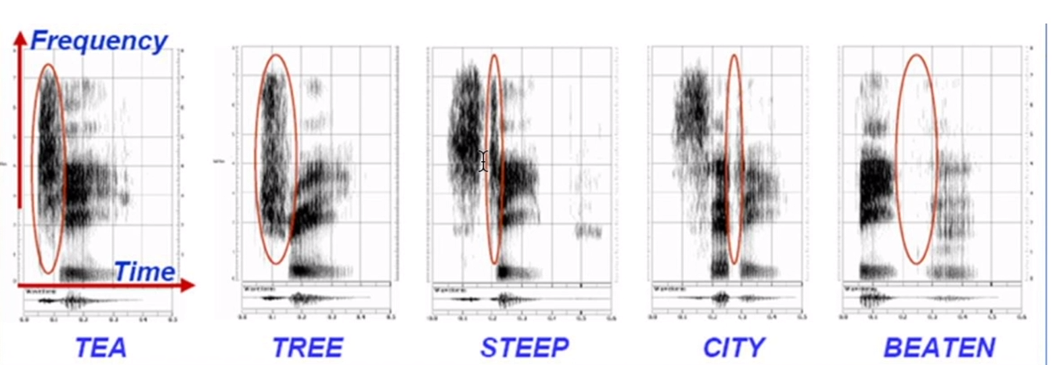
1、上下文多样性:同一个字或者字母,在不同的上下文中,发音会有所不同。下图中的字母T,在Tea、Tree等不同上下文中,发音结果的频谱表现差别很大。
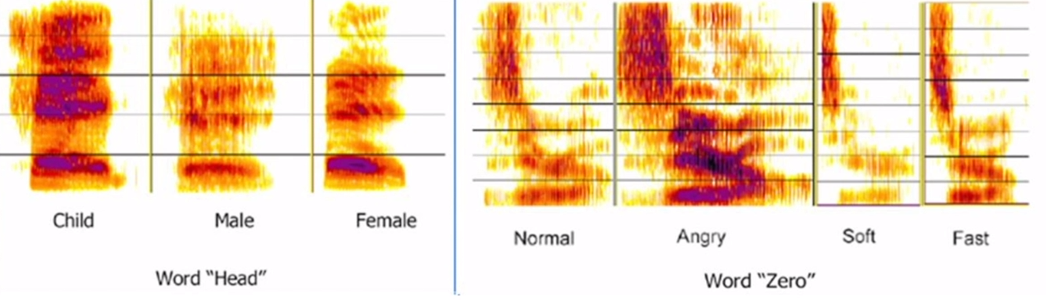
2、说话对象多样性:同一个词,不同的说话人,发音会有所不同。下图中的单词 head 和 Zero,不同的年龄和情绪状态下,发音结果的频谱表现差别很大。
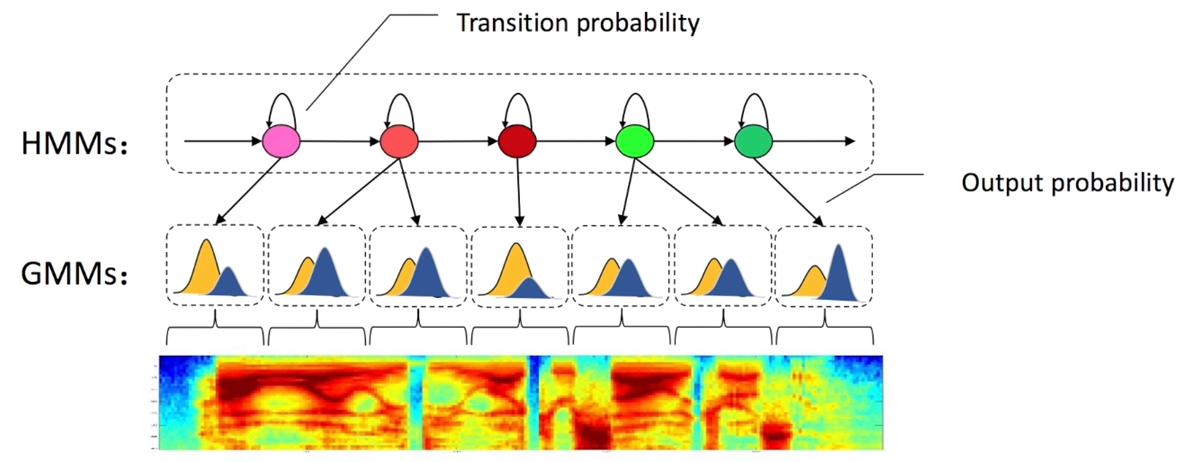
GMM-HMM
利用马尔科夫跳转概率对输入的语音信号内部状态进行建模。
利用高斯混合模型来拟合特征分布情况,这里可以认为是对马尔科夫跳转概率进行建模。
GMM-HMM的意义:提出了一个完整框架,将语音识别问题分为了多个层次。
声学建模单元的选择问题 Choice of Acoustic Modeling Unit
考虑因素:
- 准确性 Accurate
- 可训练性 Trainable
- 可泛化性(可推广性) Generalizable
尺度越小,每个建模单元上训练数据就越多,复用性就越高,可训练性、可泛化性强,但是上下文多样性会减少,准确性会变差,一般是在多个方面做一个权衡。
声母 -> 音节 -> 字 -> 词 -> 短语、句子
上下文依赖的建模单元选择 Context dependency
1、选择声母作为建模单元,假设我们有60个声母可以作为基本的建模单元,考虑上下文(前面一个声母、中间一个声母,后面一个声母),就有\(60^3\)个不同的建模单元,这样每一个建模单元能够得到的样本就很少。
2、对这 \(60^3\) 个建模单元进行聚类,因为不同的上下文,对同一个中间声母的影响是类似的,就可以把它们划归为同一类。根据数据库的实际情况,你可以把\(60^3\)个建模单元聚类成1千个或者1万个,这样的方法就很好地平衡了建模的尺度和上下文之间的关系。
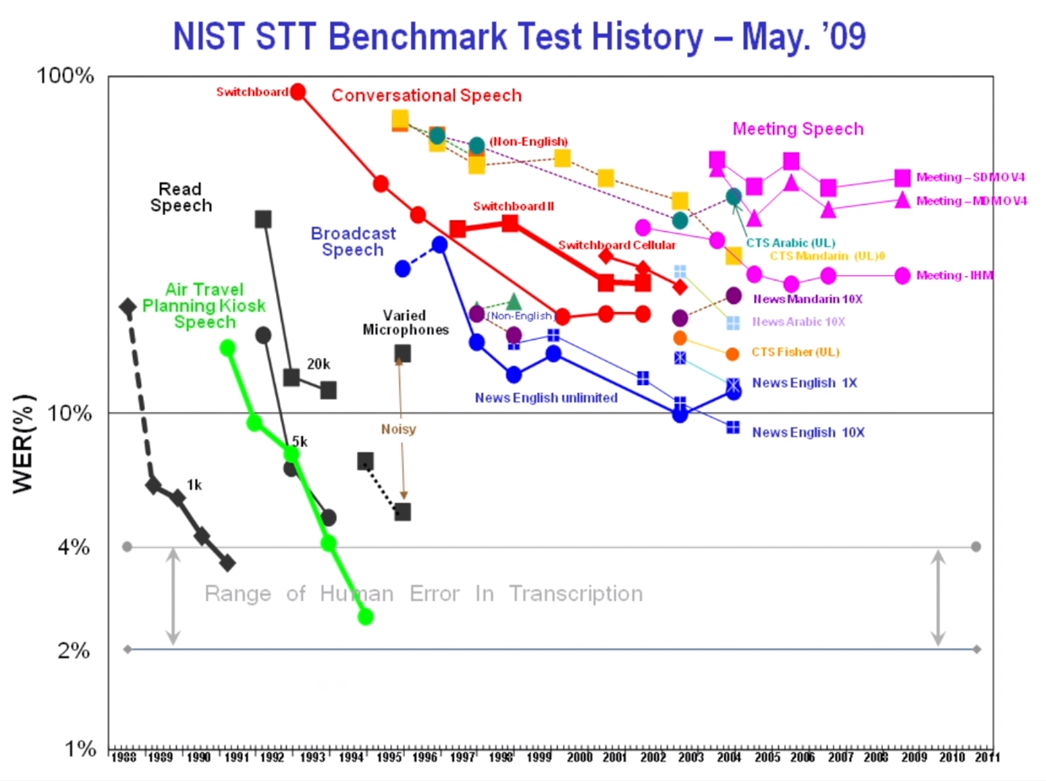
语音识别性能
脱离语音识别场景谈性能是一种耍流氓的行为
初见DNN
简单替换
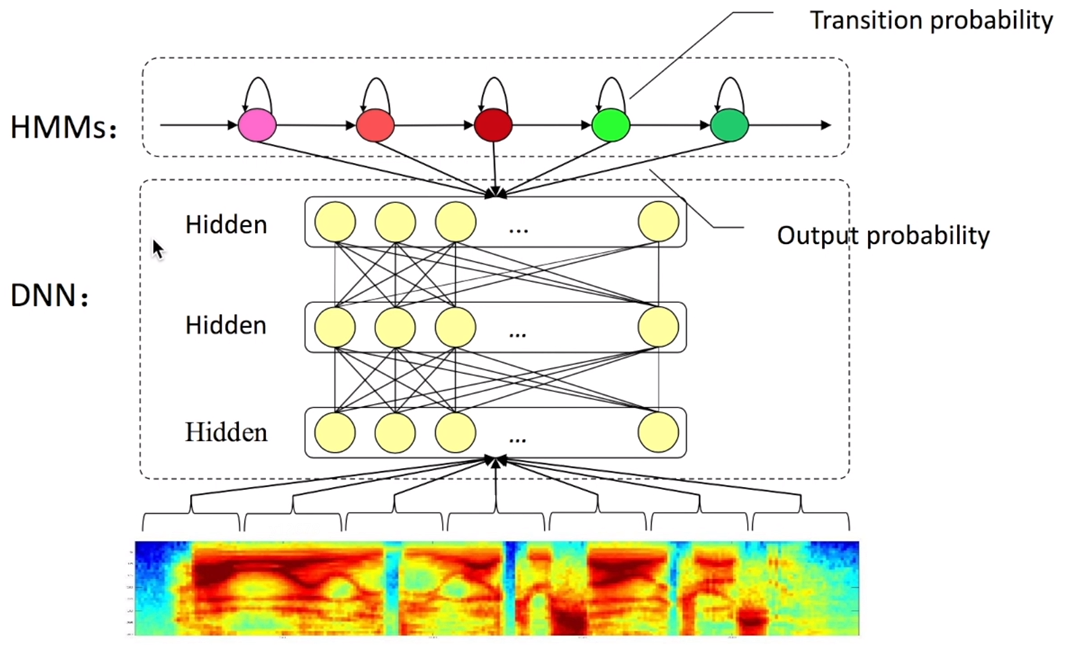
直接将GMM那一部分替换为神经网络。GMM输出的是HMM的每一个状态的likelihood(可能性),而DNN接收声学特征作为输入,输出的HMM的每一个状态的posterior probability(后验概率)。
DNN output(???) \[ y_{s_i}(t) = p(q_t = s_i|x_i) \]
\[ p(x_t|q_t=s_i) = \frac{p(q_t=s_i|x_t)p(x_t)}{p(s_i)} \cong \frac{y_{s_i}(t)}{p(s_i)} \]
经典文献
[1] G Dahl, D Yu, L Deng, A Acero . Context Dependent Pre trained Deep Neural Networks for Large Vocabulary Speech Recognition. Audio, Speech, and Language Processing, IEEE Transactions on 20(1), 30 42 [2] G. Hinton, L. Deng, D. Yu, GE. Dahl, A. Mohamed, and et.al, Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal processing magazine 29 (6), 82 97.
改进
输入特征
相关实验发现:输入特征使用Fbank的效果要好于使用MFCCs作为输入特征。原因是MFCCs增加了特征内部之间的独立性,而GMM方法有独立性要求,DNN没有这方面的要求,所以改用Fbank会好一点。
网络结构
前馈 -> 卷积 -> 循环神经网络 Feedforward -> Convolutions -> Recurrent 现在很多大公司,在线云端的ASR系统依旧采用的是LSTM+HMM的模式。
经典论文
[3] A. Graves, A. Mohamed, G. Hinton, Speech recognition with deep recurrent neural networks. ICASSP 2013. [4]O Abdel Hamid, A Mohamed, H Jiang, L Deng, G Penn, D Yu. Convolutional neural networks for speech recognition. IEEE/ACM Transactions on Audio, Speech and Language Processing, 22(10),1533 1545.
端到端系统
非端到端的混合系统:LSTM-HMM
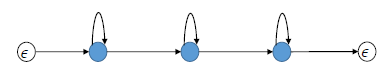
端到端系统:CTC(Connectionist Temporal Classification)
CTC算法可以对给定的X求出输出任意Y的概率。关键在于CTC如何考虑输入X和输出Y的alignment,因为X和Y的长度通常不是相同的。CTC用于ASRT还引入了blank label,解决连续词问题。
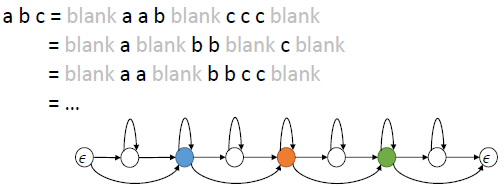
关于CTC的一切,参考博客: https://xiaodu.io/ctc-explained/ https://distill.pub/2017/ctc/ https://zhuanlan.zhihu.com/p/88645033
CTC vs. HMM
本质上一样,不过拓扑结构不同。CTC没有对输出符号之间的关系进行建模,输出符号可能会存在延迟。
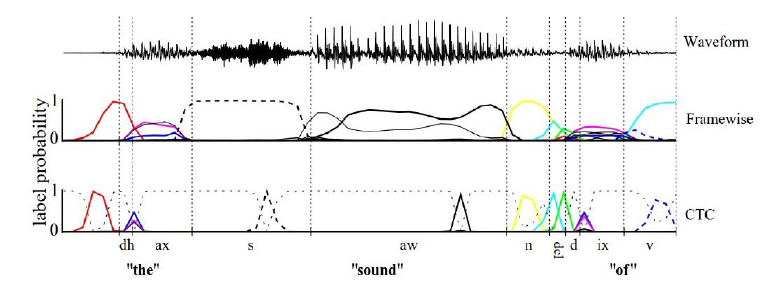
CTC算法实例:DeepSpeech System
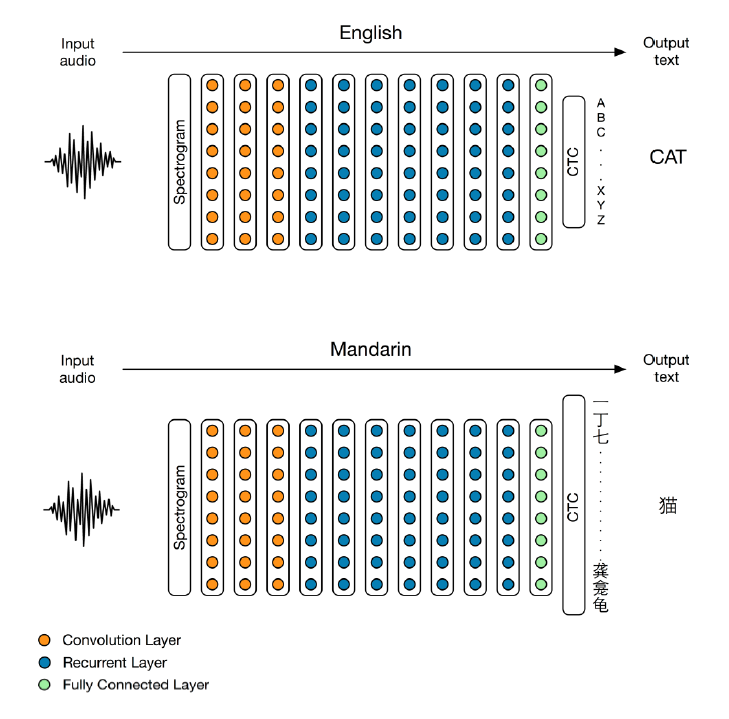
Attention ASR
sequence2sequence的Attention ASR不在需要语言模型。文本、语音一一对应的数据很难搜集,所以,数据是端到端sequence2sequence的Attention ASR效果的关键。
对比
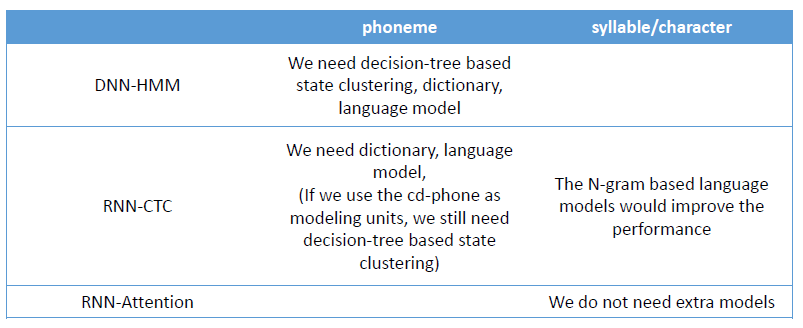
CTC到底是不是端到端的,取决于建模单元是音素(phoneme)还是音节或者字(syllable/character)。CTC或者Attention在采取音节或者字为建模单元的情况下,添加N元文法语言模型,都是可以提高效果的。
基于Attention的ASR第一篇文献: Chorowski J , Bahdanau D , Cho K , Bengio Yoshua. End-to-end Continuous Speech Recognition using Attention-based Recurrent NN: First Results[J]. Eprint Arxiv, 2014.
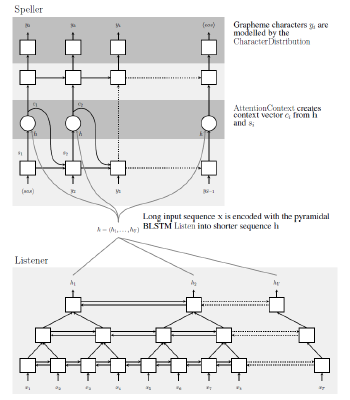
LTS System(Listen-Attend-Spell)
编码器 Encoder Listen,将输1入特征序列映射为嵌入特征 embedding feature。 解码器 Decoder Spell,将embadding feature和attention information映射为输出符号。
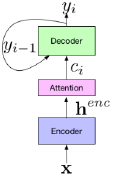
Attention VS. CTC
Attention优点: 1、无条件独立性假设 2、同时学习了声学特征和语言信息 3、结构更加简单 Attention缺点: 1、训练困难,需要更多技巧。 2、Attention需要把输入的embadding feature映射成固定维度的向量,不利于流式解码,流式解码的输入是变长的,输入的语音长度无法控制。
Tricks of LTS
1、Schedule sampling,在一个训练的batch中,有时候用Ground Truth做监督,有时候用预测值做监督。 2、Lable Smoothing,直接给输出符号加预定义噪声。(2016) 3、Multi-Task Learning,多任务学习。在Attention Decoder之外,添加CTC Decoder,Loss Function中添加CTC Decoder的结果,这样不但收敛更快,而且解码效果更好。(2017)
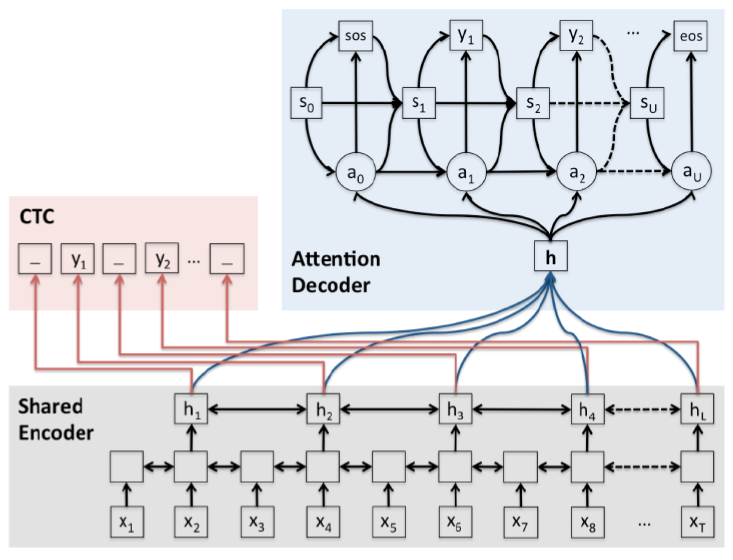
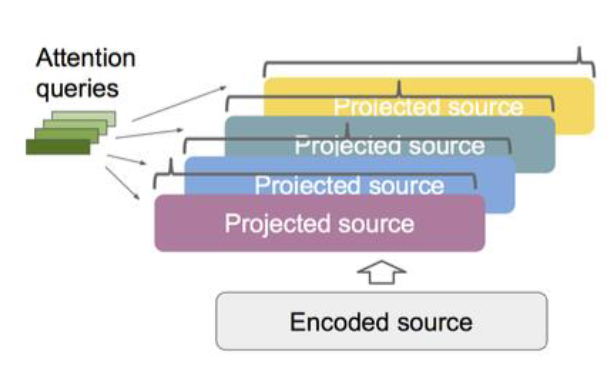
4、Multi-Headed Attention(2018)
5、SpecAugment,通过增强数据加快收敛速度。(2019)
Transducer
Online neural transducer解决Attention方法无法流式解码的问题。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!