LeetCode 44. 通配符匹配(难)
动态规划,发现两个规则,结合dp矩阵进行运算。
题目
给定一个字符串 (s) 和一个字符模式 (p) ,实现一个支持 '?' 和 '*' 的通配符匹配。
1 | |
两个字符串完全匹配才算匹配成功。
说明:
- s 可能为空,且只包含从 a-z 的小写字母。
- p 可能为空,且只包含从 a-z 的小写字母,以及字符 ? 和 *
示例
示例 1: 1
2
3
4输入:
s = "aa"
p = "a"
输出: false
示例 2: 1
2
3
4输入:
s = "aa"
p = "*"
输出: true
示例 3: 1
2
3输入:
s = "cb"
p = "?a"
示例 4: 1
2
3输入:
s = "adceb"
p = "*a*b"
示例 5: 1
2
3输入:
s = "acdcb"
p = "a*c?b"
考察知识点
贪心算法、字符串、动态规划、回溯算法
核心思想
方法一、递归
- 清理输入数据用一个星号代替多个星号:p = remove_duplicate_stars(p)。
- 初始化记忆哈希表 dp。
- 返回 helper 函数,用清理后的输入作为参数。
helper(s,p):- 如果
(s,p)已经计算过存储在dp中,则返回dp中的值。 - 如果字符串相等
p == s或p == '*',在dp添加dp[(s, p)] = True - 反之如果
p或s为空,则dp[(s, p)] = False。 - 反之如果当前字符匹配,即
p[0] == s[0]或p[0] == '?',则继续检查下一个字符并dp[(s, p)] helper(s[1:], p[1:])。 - 反之如果当前字符模式是一个星号
p[0] == '*',则有两种情况,要么不匹配字符要么匹配一个或多个字符,则dp[(s, p)] = helper(s, p[1:])orhelper(s, p[1:])。 - 反之如果
p[0] != s[0],则dp[(s, p)] = False。 - 返回
dp[(s, p)]。
- 如果
方法二、动态规划(发现两个规则,结合dp矩阵进行运算。)
将问题简化为简单的问题,例如,有一个字符串 \(adcebdk\) 和字符模式 \(\*a\*b?k\) ,计算是否匹配 D = True/False。我们将输入字符串和字符模式的长度 p_len,s_len 和是否匹配 D[p_len][s_len] 联系起来。
让我们进一步介绍 D[p_idx][s_idx],D[p_idx][s_idx] 代表的是字符模式中的第 p_idx 字符和输入字符串的第 s_idx 字符是否匹配。
规则一、字符相同或字符模式的字符为 ?,则有 D[p_idx][s_idx]=D[p_idx - 1][s_idx - 1]
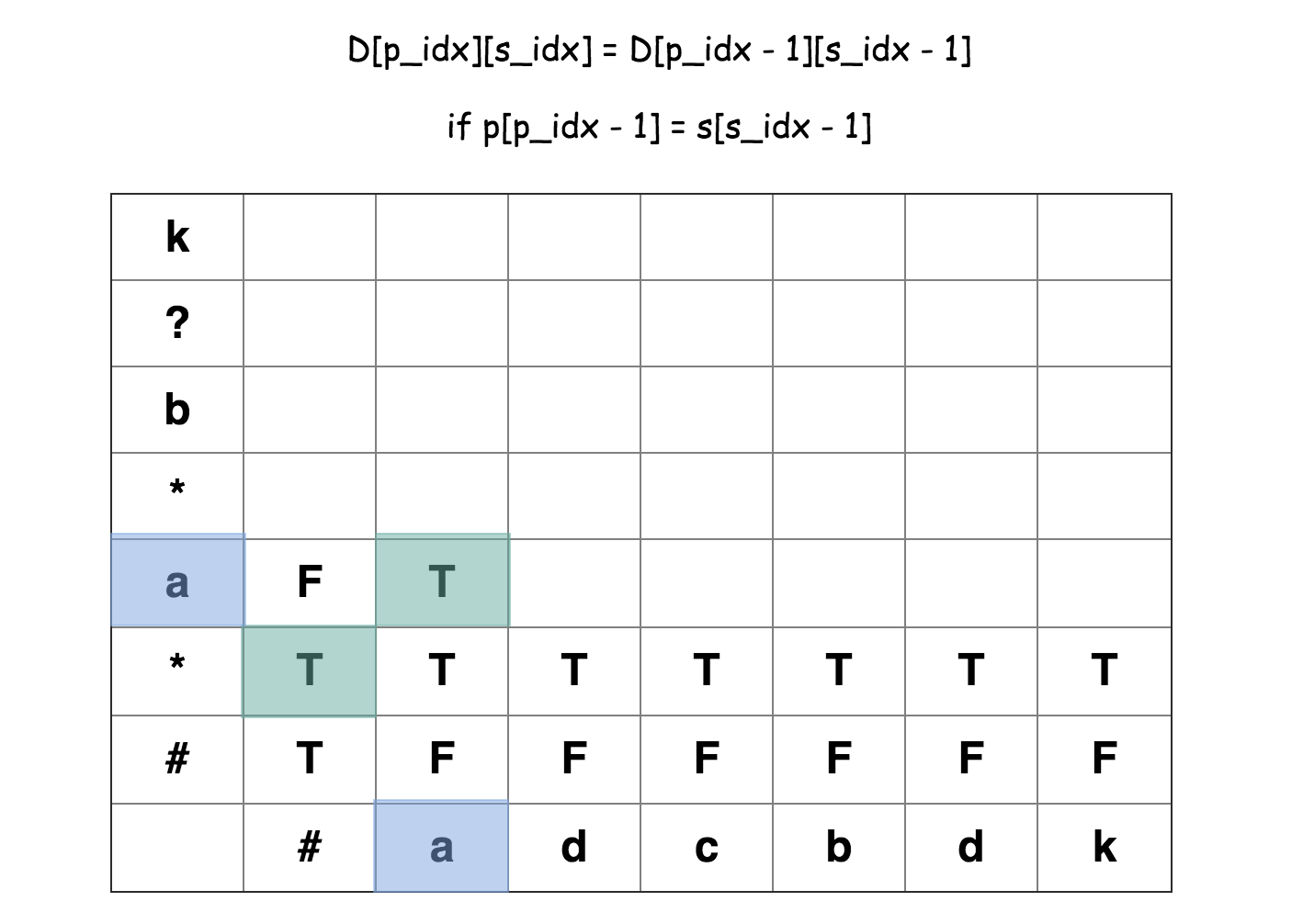
规则二、字符模式的字符为*且 D[p_idx - 1][s_idx - 1] = True,则有:
- 星号匹配完成。 - 星号继续匹配更多的字符。
即:D[p_idx - 1][i] = True, i >= s_idx - 1
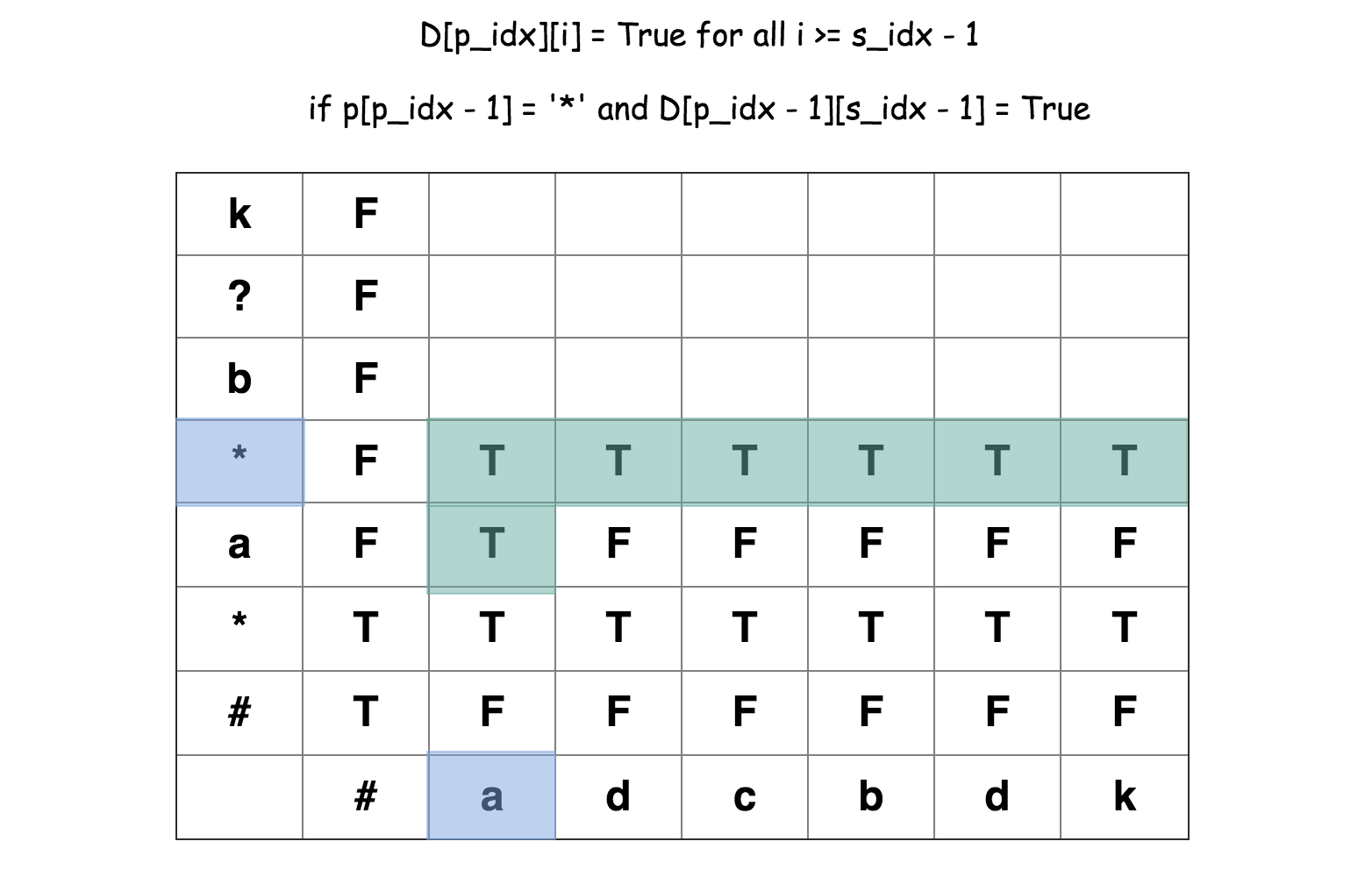
所以,每一步的计算是基于之前完成的计算完成的。
算法
初始化匹配表为 False 除了D[0][0] = True。 使用规则 1 和规则 2 计算表格,最后返回 D[p_len][s_len] 作为答案。
方法三、回溯法
复杂度 \(O(SP)\) 比 \(O(2^{\min(S, P/2)})\) 好的多,但是仍然有改进的余地。不需要计算整个表格,也就是检查每个星号的所有可能性:
匹配 0 个字符。 匹配 1 个字符。 匹配 2 个字符。
---
匹配剩余所有字符
核心思想就是:我们从匹配 0 个字符开始,如果这个假设导致不匹配,则回溯:回到前一个星号,假设它匹配一个字符,然后继续。若又是不匹配的情况?再次回溯:回到上一个星号,假设匹配两个字符,等等。

算法:
我们使用两个指针:s_idx 遍历输入字符串,p_idx 遍历字符模式。当 s_idx < s_len: - 如果字符模式仍有字符 p_idx < p_len 且指针下的字符匹配 p[p_idx] == s[s_idx] 或 p[p_idx] == '?',则两个指针向前移动。 - 反之如果字符模式仍有字符 p_idx < p_len 且 p[p_idx] == '*',则首先检查匹配 0 字符的情况,即只增加模式指针 p_idx++。记下可能回溯的位置 star_idx 和当前字符串的位置 s_tmp_idx。 - 反之如果出现不匹配的情况: - 如果字符模式中没有星号,则返回 False。 - 如果有星号,则回溯:设置 p_idx = star_idx + 1 和 s_idx = s_tmp_idx + 1,假设这次的星匹配多个字符。则可能的回溯为 s_tmp_idx = s_idx。 - 如果字符模式的所有剩余字符都是星号,则返回 True。
代码步骤
1、声明s_len、p_len、s_idx、p_idx、star_idx、s_tmp_idx等变量
2、开始while循环,循环在s_idx等于s_len的时候结束,也就string指针指到最后一位的时候结束。
2.1、如果字符模式仍有字符 p_idx < p_len 且指针下的字符匹配 p[p_idx] == s[s_idx] 或 p[p_idx] == '?',则两个指针向前移动。
2.2、反之如果字符模式仍有字符 p_idx < p_len 且 p[p_idx] == '*',则首先检查匹配 0 字符的情况,即只增加模式指针 p_idx++。记下可能回溯的位置 star_idx 和当前字符串的位置 s_tmp_idx。
2.3、反之如果如果字符模式中没有星号也不匹配,则直接返回 False。
2.4、不满足前面所有判断,说明当前没能匹配上,但是star_index != -1,也就是存在*,则回溯,让*匹配更多string中的字符:设置 p_idx = star_idx + 1 和 s_idx = s_tmp_idx + 1,假设这次的星匹配多个字符。则可能的回溯为 s_tmp_idx = s_idx。
3、结束while循环,如果字符模式的所有剩余字符都是星号,则返回 True。
Python版
方法一的实现
1 | |
时间复杂度:最好的情况下 \(O(min(S,P))\),最坏的情况下是 \(O(2^{min(S,P/2)})\)。其中 S 和 P 指的是输入字符串和字符模式的长度。 最好的情况很明显,让我们估算最坏的情况。最耗时的递归是字符模式上的星号形成树的情况,将执行两个分支 helper(s, p[1:]) 和 helper(s[1:], p)。数据清理后字符模式中的最大星树为 \(P/2\),因此时间复杂度: \(O(2^{min(S,P/2)} )\)。
空间复杂度:\(O(2^{min(S,P/2)})\),用来存储记忆哈希表和递归调用堆栈。
执行用时:1136 ms, 在所有 Python3 提交中击败了21.59%的用户
内存消耗:663.8 MB, 在所有 Python3 提交中击败了5.20%的用户
方法二的实现
1 | |
时间复杂度:\(O(SP)\),其中 S 和 P 指的是字符模式和输入字符串的长度。
空间复杂度:\(O(SP)\),用来存储匹配表格。
执行用时 :472 ms, 在所有 Python3 提交中击败了78.11%的用户。
内存消耗 :21.5 MB, 在所有 Python3 提交中击败了52.60%的用户。
方法三的实现
1 | |
时间复杂度:最好的情况下是 \(O(min(S,P))\),平均情况下是 \(O(S \log P)\),其中 S 和 P 指的是字符模式和输入字符串的长度。详细证明可点击:证明过程。
空间复杂度:\(O(1)\)。
执行用时 :84 ms, 在所有 Python3 提交中击败了82.88%的用户。
内存消耗 :13.5 MB, 在所有 Python3 提交中击败了87.95%的用户。
有效语法糖
1、all() 函数,当可迭代对象(list、set)中全为真值时,返回 True。
1 | |
2、一种更加简洁的if条件写法
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!