LeetCode 10. 正则表达式匹配(难)& 面试题19. 正则表达式匹配(难)
从递归回溯到动态规划实现正则匹配
题目
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 . 和 * 的正则表达式匹配。
. 匹配任意单个字符 * 匹配或多个前面的那一个元素 所谓匹配,是要涵盖整个字符串 s 的,而不是部分字符串。
说明: s 可能为空,且只包含从 a-z 的小写字母。 p 可能为空,且只包含从 a-z 的小写字母,以及字符 . 和 *。
测试用例
功能测试(模式字符串里包含普通字符、、”*”;模式字符串和输入字符串匹配/不匹配)。 特殊输入测试(输入字符串和模式字符串是nullptr、空字符串)。
考点
考查应聘者对字符串的编程能力。考查应聘者对正则表达式的理解。 考查应聘者思维的全面性。应聘者要全面考虑普通字符、和*并分别分析它们的匹配模式。在应聘者写完代码之后,面试官会要求他/她测试自己的代码。这时候应聘者要充分考虑普通字符、. 和 *三者的排列组合,尽量完备地想出所有可能的测试用例。
示例
示例 1:
1 | |
解释: "a" 无法匹配 "aa" 整个字符串。
示例 2:
1 | |
解释: 因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。
示例 3:
1 | |
解释: ".*" 表示可匹配零个或多个('*')任意字符('.')。
示例 4:
1 | |
解释: 因为 '*' 表示零个或多个,这里 'c' 为 0 个, 'a' 被重复一次。因此可以匹配字符串 "aab"。
示例 5:**
1 | |
考察知识点
动态规划、回溯算法
核心思想
递归
要实现正则匹配,就要做三件事情: 1、对第一个字符进行匹配:first_match = bool(text) and pattern[0] in {text[0], '.'} 2、当模式中的第二个字符是*时,问题要复杂一些,因为可能有多种不同的匹配方式。一种选择是在字符串不变,模式向后移动两个字符,self.isMatch(text, pattern[2:])。这相当于*和它前面的字符被忽略了,因为*可以匹配字符串中的0个字符。另一种选择是如果模式中的第一个字符和字符串中的第一个字符相匹配,则在字符串上向后移动一个字符,模式保持不变,first_match and self.isMatch(text[1:], pattern)。 3、当模式中的第二个字符不是*时,问题要简单很多。如果字符串中的第一个字符和模式中的第一个字符相匹配,那么在字符串和模式上都向后移动一个字符,然后匹配剩余的字符串和模式。如果字符串中的第一个字符和模式中的第一个字符不相匹配,则直接返回false。return first_match and self.isMatch(text[1:], pattern[1:])
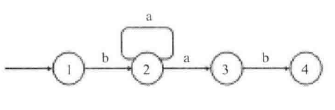
如下图,当匹配进入状态2并且字符串的字符是a时,我们有两种选择,进入状态3(字符串不变,模式向后移动两个字符),也可以保持在状态2不变(字符串向后移动一个字符,模式保持不变)。
动态规划
在递归的代码的基础上,添加mome保存中间结果,自下而上的解决问题。 有的读者也许会问,你怎么知道这个问题是个动态规划问题呢,你怎么知道它就存在「重叠子问题」呢,这似乎不容易看出来呀? 解答这个问题,最直观的应该是随便假设一个输入,然后画递归树,肯定是可以发现相同节点的。这属于定量分析,其实不用这么麻烦,下面我来教你定性分析,一眼就能看出「重叠子问题」性质。 先拿最简单的斐波那契数列举例,我们抽象出递归算法的框架:
1 | |
看着这个框架,请问原问题 f(n) ,如何触达子问题 f(n - 2)?有两种路径,一是 f(n) -> f(n-1) -> f(n - 1 - 1), 二是 f(n) -> f(n - 2)。前者经过两次递归,后者进过一次递归而已。两条不同的计算路径都到达了同一个问题,这就是「重叠子问题」,而且可以肯定的是,只要你发现一条重复路径,这样的重复路径一定存在千万条,意味着巨量子问题重叠。 同理,对于本问题,我们依然先抽象出算法框架:
1 | |
提出类似的问题,请问如何从原问题 dp(i, j),触达子问题 dp(i + 2, j + 2)?至少有两种路径,一是 dp(i, j) -> #3 -> #3,二是 dp(i, j) -> #1 -> #2 -> #2。因此,本问题一定存在重叠子问题,一定需要动态规划的优化技巧来处理。
详情可以查看链接,由浅及深,讲述的非常准确。 参考连接
Python版本
- 递归回溯,暴力破解方法。
1 | |
- 动态规划
1 | |
- 去注释简洁版本
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!