TCP协议流量控制过程
TCP协议使用窗口字段和一系列算法实现拥塞控制 Congestion control of TCP
什么是 TCP 拥塞控制
1)、TCP 拥塞控制的目标是最大化利用网络上瓶颈链路的带宽。
简单来说是将网络链路比喻成一根水管,如果我们希望尽可能地使用网络传输数据,方法就是给水管注水,就有如下公式:
水管内的水的数量 = 水管的容积 = 水管粗细 × 水管长度
对应的网络名词就是:
网络内尚未被确认收到的数据包数量 = 网络链路上能容纳的数据包数量 = 链路带宽 × 往返延迟
为了保证水管不会爆管,TCP 维护一个拥塞窗口cwnd(congestion window),用来估计在一段时间内这条链路(水管中)可以承载和运输的数据(水)的数量,拥塞窗口的大小取决于网络的拥塞程度,并且动态地在变化,但是为了达到最大的传输效率,我们该如何知道这条水管的运送效率是多少呢?
一个简单的方法就是不断增加传输的水量,直到水管破裂(对应到网络上就是发生丢包)为止,用 TCP 的描述就是: 只要网络中没有出现拥塞,拥塞窗口的值就可以再增大一些,以便把更多的数据包发送出去,但只要网络出现拥塞,拥塞窗口的值就应该减小一些,以减少注入到网络中的数据包数。
2)、简而言之:TCP协议采用单位为字节,大小可变的滑动窗口进行流量控制。窗口值就是给对方设置的发送窗口上限,当TCP链接建立时由发送方和接收方协商确定,在传输过程中会动态变化。拥塞窗口的窗口值在标志字段(URG---FIN)的后面,一共占16个bit位。
如何确定滑动窗口大小?
确定滑动窗口的大小一般取"接收端窗口"和"拥塞窗口"较小的那一个。
- 接收端窗口(rwnd): 接收端根据其目前的接收缓存大小所许诺的最新的窗口值,是来自接收端的流量控制。接收端将此窗口值放在 TCP 报文的首部中的窗口字段,传送给发送端。
- 拥塞窗口(cwnd): 发送端根据自己估计的网络拥塞程度而设置的窗口值,是来自发送端的流量控制。发送端将此窗口值放在 TCP 报文的首部中的窗口字段,传送给接收端。
知道接收端目前的”接收缓存大小“很容易,所以,接收端窗口(rwnd)可以定量确定,但是"网络拥塞程度"很难定量确定。所以滑动窗口大小主要由拥塞窗口大小决定。
常见的 TCP 拥塞控制算法
历史沿革
1988年,首次提出TCP拥塞控制算法由慢开始和拥塞避免算法组成(Tahoe Version)。 1990年,在之前的基础上加入了快重传和快恢复算法构成新的TCP拥塞控制算法,是目前使用较为广泛的版本也是Linux 内核默认的拥塞控制算法算法。(Reno Version) 2016年,Google提出的一种新的拥塞控制算法,BBR。
Reno
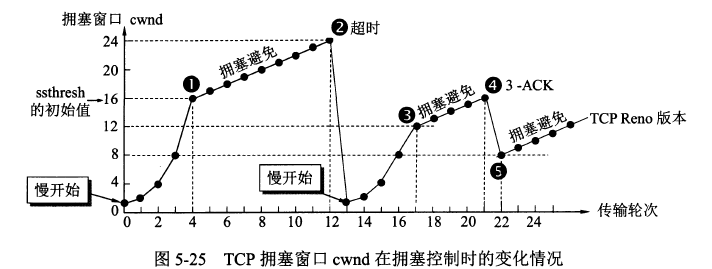
Reno 被许多教材(例如:《计算机网络——自顶向下的方法》)所介绍,适用于低延时、低带宽的网络,它将拥塞控制的过程分为四个阶段:慢启动、拥塞避免、快重传和快恢复。
慢启动阶段(cwnd指数增大)[发送方]
思路是不要一开始就发送大量的数据,先探测一下网络的拥塞程度,也就是说由小到大逐渐增加拥塞窗口(cwnd,congestion window)的大小,在没有出现丢包时每收到一个ACK报文就将拥塞窗口大小加一(单位是 MSS,最大单个报文段长度),每个传输轮次(也就是RTT/Round-Trip Time,往返时延)发送窗口增加一倍,呈指数增长。最大单个报文段长度MSS选项是TCP协议定义的一个选项,MSS选项用于在TCP连接建立时,收发双方协商通信时每一个报文段所能承载的最大数据长度。
拥塞避免阶段(cwnd线性增大)[发送方]
当窗口达到慢启动阈值/慢开始门限(slow start threshold/ssthresh)或出现丢包时,进入拥塞避免阶段,窗口每轮次加一(加法增大),呈线性增长;
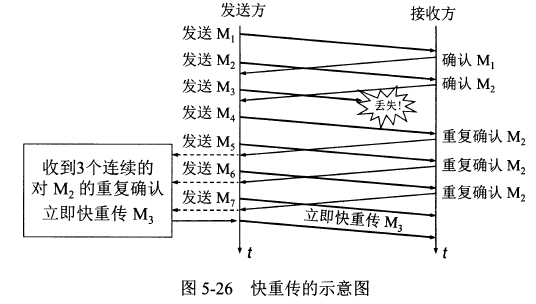
快重传阶段 [接收方/发送方]
快重传机制要求接收方在收到一个失序的报文段后就立即发出与之前重复的确认ACK而不要等到自己发送数据时捎带确认;当发送方收到对一个报文的三个重复的 ACK 时,认为这个报文的下一个报文丢失了,这时就立即重发这个丢失的报文,而不用等待为该报文设置的重传计时器到期之后再重发。由于快重传使发送方及早知道有报文段没有到达对方,可提高网络吞吐量约20%。
这里举一个例子来理解快重传,如图所示,接收方收到了M1和M2后都分别及时发出了确认。现假定接收方没有收到M3但却收到了M4。本来接收方可以什么都不做。但按照快重传算法,接收方必须立即发送对M2的重复确认,以便让发送方及早知道接收方没有收到报文段M3。发送方接着发送M5和M6。接收方收到后也仍要再次分别发出对M2的重复确认。这样,发送方共收到了接收方的4个对M2的确认,其中后3个都是重复确认。快重传算法规定,发送方只要一连收到3个重复确认,就知道接收方确实没有收到报文段M3,因而应当立即进行重传(即“快重传”),这样就不会出现超时,发送方也不就会误认为出现了网络拥塞。使用快重传可以使整个网络的吞吐量提高约20%。
快恢复阶段 [发送方]
快重传完成后进入快恢复阶段,将慢启动阈值修改为当前拥塞窗口值的一半(乘法减半)。同时拥塞窗口值等于更新之后的慢启动阈值(也就是快重传阶段时的拥塞窗口值的一半),然后进入拥塞避免阶段,重复上述过程。
注意:如果使用的不是Reno算法是原始的Tahoe算法,那么不会有快恢复阶段,当网络出现时间延迟或者丢包时,也会将慢启动阈值修改为当前拥塞窗口值的一半(乘法减半),但拥塞窗口值不再是之前拥塞窗口值的一半,而是置为 1个单位的最大单个报文段长度MSS,重新进入慢开始阶段。
整体过程如下图所示,从第1个传输轮次到第13个传输轮次,一般初始的cwnd=1个单位MMS。
BBR
BBR 是谷歌在 2016 年提出的一种新的拥塞控制算法,已经在 Youtube 服务器和谷歌跨数据中心广域网上部署,据 Youtube 官方数据称,部署 BBR 后,在全球范围内访问 Youtube 的延迟降低了 53%,在时延较高的发展中国家,延迟降低了 80%。
BBR 算法不将出现丢包或时延增加作为拥塞的信号,而是认为当网络上的数据包总量大于瓶颈链路带宽和时延的乘积时才出现了拥塞,所以 BBR 也称为基于拥塞的拥塞控制算法(Congestion-Based Congestion Control),其适用网络为高带宽、高时延、有一定丢包率的长肥网络,可以有效降低传输时延,并保证较高的吞吐量,与其他两个常见算法发包速率对比如下:
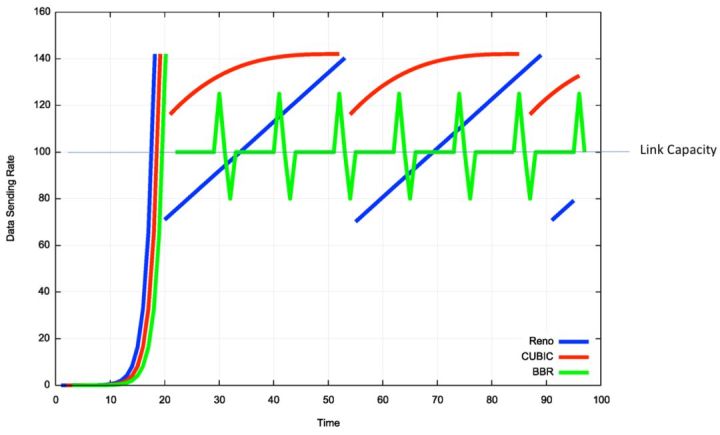
BBR 算法周期性地探测网络的容量,交替测量一段时间内的带宽极大值和时延极小值,将其乘积作为作为拥塞窗口大小,使得拥塞窗口始的值始终与网络的容量保持一致。
所以 BBR 算法解决了两个比较主要的问题:
- 在有一定丢包率的网络链路上充分利用带宽。适合高延迟、高带宽的网络链路。
- 降低网络链路上的 buffer 占用率,从而降低延迟。适合慢速接入网络的用户。
总结
目前有非常多的 TCP 的拥塞控制协议,例如:
基于丢包的拥塞控制:将丢包视为出现拥塞,采取缓慢探测的方式,逐渐增大拥塞窗口,当出现丢包时,将拥塞窗口减小,如 Reno、Cubic 等。
基于时延的拥塞控制:将时延增加视为出现拥塞,延时增加时增大拥塞窗口,延时减小时减小拥塞窗口,如 Vegas、FastTCP 等。
基于链路容量的拥塞控制:实时测量网络带宽和时延,认为网络上报文总量大于带宽时延乘积时出现了拥塞,如 BBR。
基于学习的拥塞控制:没有特定的拥塞信号,而是借助评价函数,基于训练数据,使用机器学习的方法形成一个控制策略,如 Remy。
从使用的角度来说,我们应该根据自身的实际情况来选择自己机器的拥塞控制协议(而不是跟风 BBR),同时对于拥塞控制原理的掌握(尤其是掌握 Reno 的控制机理和几个重要阶段)可以加强对于网络发包机制的了解,在排查问题或面对面试的时候有更好的表现。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!